
L’arrivée de Gemma 4 marque un tournant que nous, ingénieurs d’infrastructure, attendions de pied ferme. On ne parle plus ici d’une simple itération incrémentale de « LLM » (Large Language Model), mais d’une véritable architecture multimodale native, pensée dès le départ pour la performance brute et la flexibilité de déploiement. Google DeepMind vient de libérer une famille de modèles (sous licence Apache 2) qui bouscule le rapport habituel entre puissance de calcul et qualité de réponse.
Le passage à la multimodalité totale (texte, image, audio, vidéo) dans des formats capables de tourner sur des stations de travail standard, voire sur du matériel « edge », change radicalement la donne pour nos pipelines de production.
1. Analyse Technique : L’Architecture sous le Capot
Gemma 4 ne se contente pas d’empiler des couches de Transformers. L’architecture introduit plusieurs mécanismes sophistiqués pour optimiser le flux de données et la gestion de la mémoire vive, ce qui est le nerf de la guerre en infrastructure.
L’Attention Hybride : Sliding Window vs Global Context
L’une des innovations majeures réside dans la gestion de l’attention. Au lieu d’utiliser une attention globale sur toute la fenêtre de contexte (ce qui est extrêmement coûteux en calcul, croissant de manière quadratique), Gemma 4 alterne :
- Sliding-window attention (SWA) : Des couches d’attention locale (512 tokens pour les petits modèles, 1024 pour les gros) qui limitent le voisinage de calcul et réduisent drastiquement la charge GPU.
- Global full-context attention : Des couches classiques intercalées pour maintenir la cohérence globale.
Pour gérer cette dualité, Google utilise un Dual RoPE (Rotary Positional Embeddings). Un RoPE standard pour les fenêtres glissantes et un RoPE « proportionnel » pour les couches globales. C’est ce qui permet aux modèles de tenir des fenêtres de contexte allant jusqu’à 256k tokens sans que la latence n’explose au premier prompt.
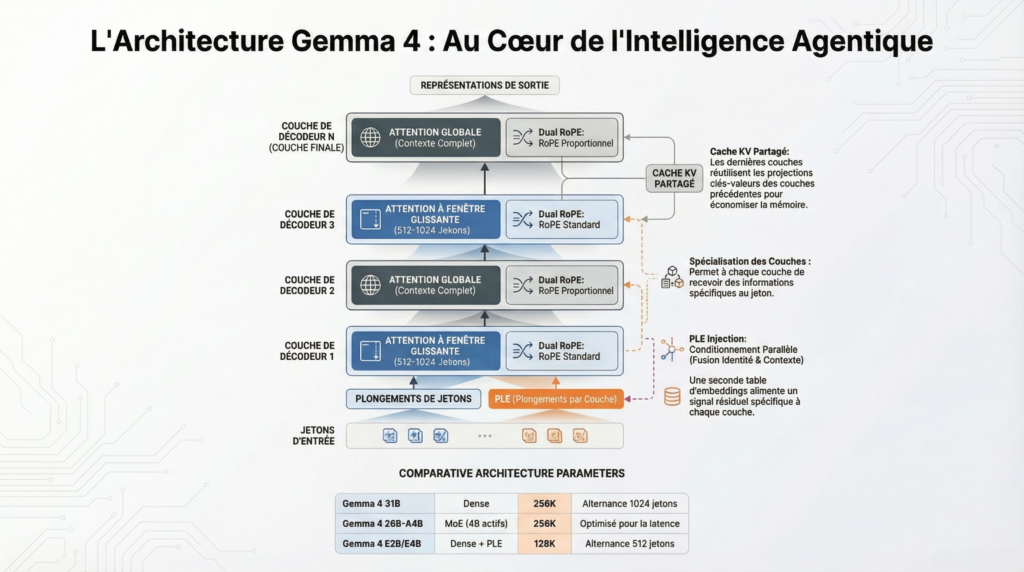
Per-Layer Embeddings (PLE) : La fin du goulot d’étranglement initial
Dans un modèle classique, l’embedding initial doit contenir toute l’information sémantique que les couches suivantes vont traiter. Gemma 4 introduit les PLE. C’est un second tableau d’embeddings, de dimension plus faible, qui injecte un signal résiduel spécifique à chaque couche du décodeur.
Concrètement, chaque couche reçoit une information « fraîche » sur l’identité des tokens, ce qui permet au modèle d’être beaucoup plus fin dans son raisonnement multimodal sans augmenter massivement le nombre total de paramètres.
Shared KV Cache : L’optimisation critique de la VRAM
Pour nous, les Ops, le « KV Cache » est souvent ce qui sature la mémoire vidéo lors des phases de génération longue. Gemma 4 implémente un Shared KV Cache. Les dernières couches du modèle ne recalculent pas leurs propres projections de clés (K) et de valeurs (V) ; elles réutilisent celles des couches précédentes.
Le gain est immédiat : moins de calculs de projection et une empreinte mémoire réduite pour le cache de contexte, sans perte de qualité mesurable sur les benchmarks.
2. Impacts sur l’Infrastructure : Dimensionnement et Performance
Le déploiement de Gemma 4 impose de repenser nos quotas de ressources. Voici un tableau récapitulatif des modèles pour nous aider à calibrer nos instances :
Tableau des caractéristiques et tailles de fichiers (Estimations Infra)
| Modèle | Paramètres (Effectifs / Totaux) | Fenêtre Contexte | Taille Fichier (FP16) | Taille Fichier (4-bit) | Usage Cible |
| Gemma 4 E2B | 2.3B / 5.1B* | 128k | ~10.2 Go | ~3.2 Go | Smartphone, Edge, IoT |
| Gemma 4 E4B | 4.5B / 8.0B* | 128k | ~16.0 Go | ~5.0 Go | Laptop, Serveur léger |
| Gemma 4 26B (MoE) | 4B (actifs) / 26B | 256k | ~52.0 Go | ~15.5 Go | Workstation, Inference Cloud |
| Gemma 4 31B (Dense) | 31B / 31B | 256k | ~62.0 Go | ~18.5 Go | Cluster GPU, Recherche |
*Incluant les tables d’embeddings et PLE.
Le cas particulier du modèle Mixture-of-Experts (MoE)
Le modèle 26B est particulièrement intéressant d’un point de vue infrastructure. Bien qu’il pèse 26 milliards de paramètres (ce qui impacte le stockage et la VRAM nécessaire pour charger le modèle), il n’utilise que 4 milliards de paramètres actifs par token lors de l’inférence.
Impact concret : Vous avez besoin d’une carte avec au moins 24 Go de VRAM (ou une quantification agressive) pour le charger, mais le débit de tokens (tokens/sec) sera proche de celui d’un modèle 4B. C’est le meilleur compromis latence/intelligence du moment.
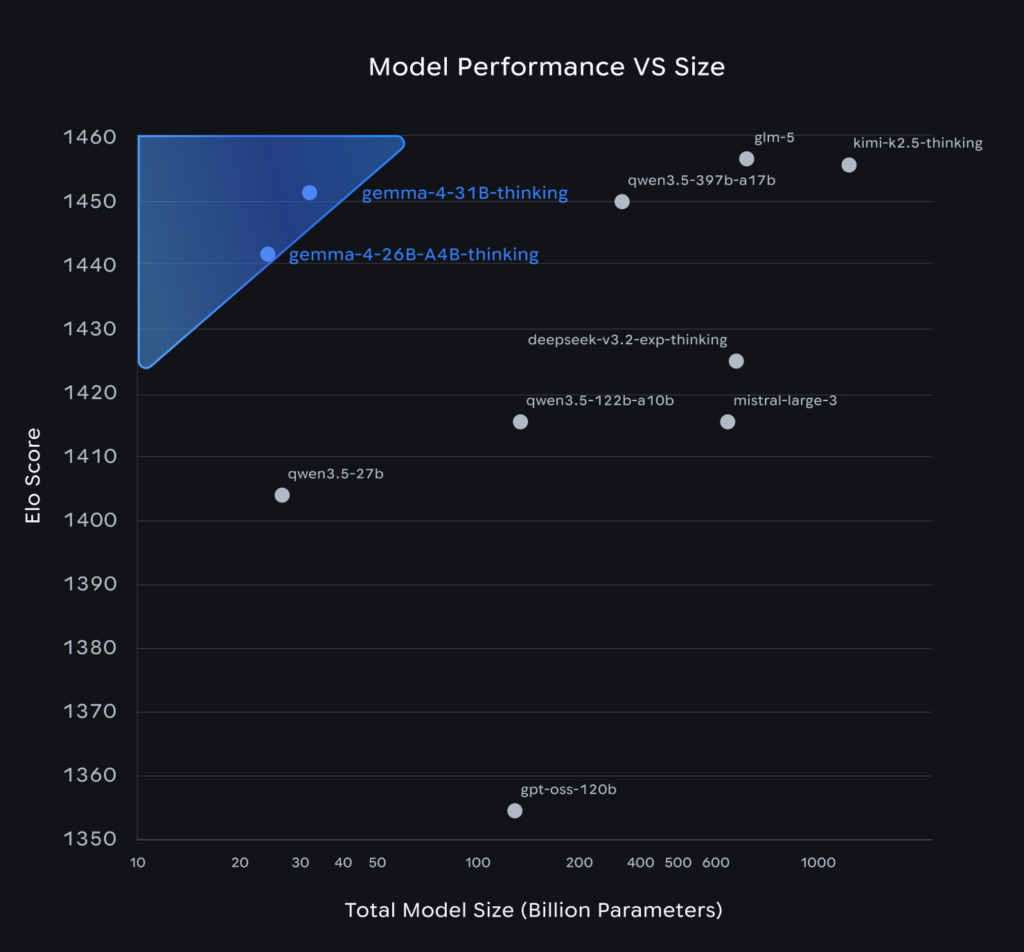
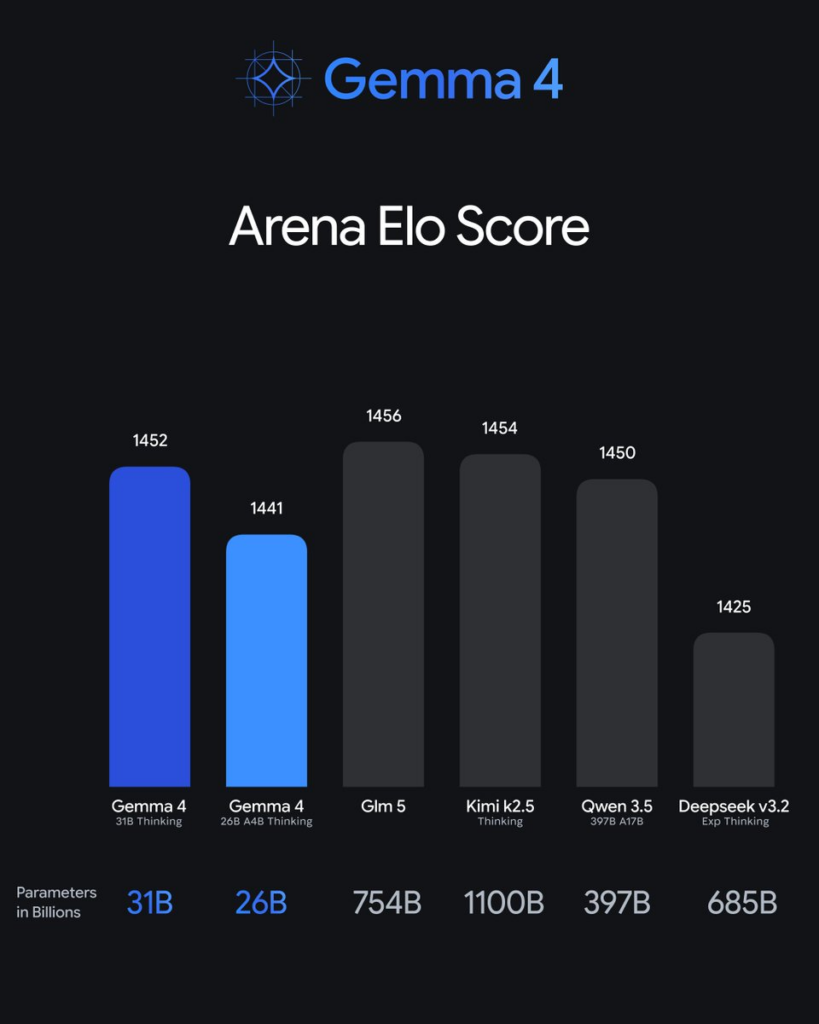
Gestion de la Multimodalité native
Gemma 4 intègre des encodeurs Vision et Audio directement dans le flux. L’encodeur vision supporte des ratios d’aspect variables et permet de configurer le nombre de tokens d’image (de 70 à 1120). En production, cela signifie que vous pouvez ajuster dynamiquement la charge de calcul en fonction de la précision d’image requise. Un OCR sur un document complexe demandera 1120 tokens, tandis qu’une simple reconnaissance d’objet se contentera de 70 tokens, économisant ainsi de précieux cycles GPU.
3. Recommandations : Mise en œuvre et Optimisation
Pour intégrer Gemma 4 dans vos environnements, voici les chemins critiques à privilégier.
Choix de la quantification
Ne restez pas en FP16 sauf si vous faites du fine-tuning. Pour l’inférence de production :
- Quantification 4-bit (GGUF/EXL2) : Indispensable pour faire tourner le modèle 31B ou 26B sur une seule carte type RTX 3090/4090 ou A10G.
- Quantification 8-bit (bitsandbytes) : Le « sweet spot » pour les modèles E2B et E4B si vous voulez conserver une précision quasi-parfaite en environnement critique.
Stack de déploiement
- Local / On-device : Utilisez
llama.cppouMLX(pour les puces Apple Silicon). La gestion du cache KV partagé y est déjà optimisée. - Cloud / Serveur : Privilégiez
vLLMouTGI(Text Generation Inference). Ces moteurs gèrent nativement le « Paged Attention », ce qui, couplé à la fenêtre de 256k de Gemma 4, permet de servir des contextes massifs sans crash mémoire. - Web / Browser : Grâce à
transformers.js, le modèle E2B est désormais utilisable directement côté client en WebGPU. C’est une option majeure pour réduire vos coûts d’infrastructure serveur en déportant l’inférence sur le device de l’utilisateur.
Configuration Système (Exemple CLI)
Pour tester rapidement le modèle E4B sur une machine Linux avec Python :
Bash
pip install -U transformers accelerate bitsandbytes
Python
from transformers import Gemma4ForCausalLM, AutoProcessor
import torch
model_id = "google/gemma-4-e4b-it"
# Chargement optimisé en 4-bit pour économiser la VRAM
model = Gemma4ForCausalLM.from_pretrained(
model_id,
device_map="auto",
quantization_config=BitsAndBytesConfig(load_in_4bit=True)
)
Conclusion
Gemma 4 n’est pas seulement une réussite algorithmique, c’est une leçon d’optimisation d’infrastructure. En combinant intelligemment l’attention hybride, les PLE et le partage de cache KV, Google livre des modèles qui « respirent » mieux sur notre hardware actuel.
Pour les équipes Infra, le message est clair : la barrière à l’entrée pour l’IA multimodale de haute qualité vient de s’effondrer. Le modèle 26B MoE, en particulier, va devenir le standard pour les agents autonomes nécessitant rapidité et compréhension contextuelle étendue. Il est temps de mettre à jour vos clusters et de commencer à benchmarker ces modèles sur vos données métiers.

Source : https://huggingface.co/blog/gemma4