
Fais le tour des réseaux sociaux et tu tomberas vite sur le même argument, répété en boucle : « l’IA en local, c’est gratuit, tu ne paies pas les tokens ». C’est l’argument massue, celui qui fait briller les yeux et sortir la carte bleue.
Sauf que c’est faux. L’IA en local, tu la paies deux fois : une fois à l’achat du matériel, et une deuxième fois en consommation électrique, mois après mois, tant que la machine tourne. Le cloud te facture au token ; le local te facture en watts. Dans les deux cas, il y a un compteur qui tourne. Il est juste moins visible côté local, parce qu’il se planque dans ta facture EDF au lieu d’arriver par mail à la fin du mois.
Et tu risques d’être surpris par le montant. Plus loin dans l’article, je te montre ma propre facture sur douze mois, relevé fournisseur à l’appui. Spoiler : ce n’est pas anodin.
Ça ne veut pas dire que le local est une mauvaise idée. Au contraire, sur certains usages c’est imbattable, et tu gardes la main sur tes données et tes modèles sans dépendre d’une API qui peut changer ses CGU ou ses prix du jour au lendemain. Ça veut juste dire qu’il faut acheter en connaissance de cause, avec les deux factures en tête, pas une seule.
Donc avant de claquer un budget, posons les bases. Et la première règle, celle qui détermine tout le reste, tient en une phrase : en IA locale, tu n’achètes pas de la puissance de calcul, tu achètes de la mémoire.
La règle de base : la mémoire d’abord
Toute la littérature sérieuse 2026 dit la même chose. Tu choisis d’abord la quantité de mémoire (VRAM sur un GPU, ou mémoire unifiée sur un mini-PC / un Mac), et ensuite seulement le reste.
Les repères à garder en tête :
- 8–16 Go : modèles 7B en quantifié. Du RAG léger, des petits agents, de l’expérimentation.
- 24 Go : 32B utilisables en Q4/Q5 (Qwen 2.5-Coder 32B, Mistral Small). Le vrai point de bascule pour bosser sérieusement.
- 40 Go+ ou mémoire unifiée 64–192 Go : 70B quantifiés (Llama 3.3 70B, DeepSeek R1 distill 70B, Qwen 2.5 72B), voire du 120B en 4-bit.
Un détail qu’on oublie souvent : la bande passante mémoire détermine ta vitesse en tokens/seconde. Une RTX 3090 tape dans les ~936 Go/s, un boîtier AMD à mémoire unifiée plafonne souvent autour de ~120 Go/s, un Mac M4 Pro est à 273 Go/s. À mémoire égale, ça change tout sur le ressenti en inférence. Avoir 64 Go ne sert à rien si le modèle crache 4 tok/s.
Les familles de matériel
Avant les tranches de budget, il faut distinguer les formes de produit, parce qu’on compare souvent des trucs qui n’ont rien à voir.
GPU grand public (GeForce). Le meilleur rapport perf/prix pour du LLM + image classique. RTX 3060, 4060 Ti, 3090, 4090, 5090. Le marché de l’occasion est ton ami.
Mini-PC IA à mémoire unifiée. Ryzen AI Max (Strix Halo), Minisforum, GMKtec, Mac mini/Studio. Beaucoup de mémoire, faible conso, format compact. En contrepartie, une bande passante plus faible que les gros GPU (sauf Apple).
Cartes data center détournées. Tesla P100, T4, P4, V100 récupérées d’occasion et collées dans une tour ATX. Beaucoup de VRAM pour pas cher, mais c’est un truc de bricoleur Linux (cooling à ajouter, drivers data center, pas de sortie vidéo).
Edge / embarqué (Jetson). Orin Nano, AGX Orin, Thor. Conso ultra-basse, format NUC, parfait pour de l’always-on silencieux ou du RAG embarqué. Pas pour du gros LLM à la maison.
Stations IA compactes premium. DGX Spark, Mac Studio haut de gamme. 128 Go+ de mémoire unifiée, cher, mais redoutable en perf/watt.
Par tranche de budget
Petite précaution avant de lire : les prix ci-dessous sont des prix observés mi-2026 sur le marché français/européen (occasion comprise). Ça bouge vite, parfois dans le mauvais sens : les Jetson Orin Nano ont pris une grosse hausse ces derniers mois, et le marché de l’occasion réserve des absurdités (un Mac mini M1 d’occasion peut coûter plus cher qu’un M4 neuf… cherchez la logique).
Moins de 400 €

L’entrée de gamme. Tu vises du 7B quantifié et du RAG léger.
- RTX 3060 12 Go d’occasion : le classique. CUDA partout, ça marche, point.
- Tesla P4 8 Go ou P100 16 Go d’occasion (~150–250 €) : énormément de VRAM par euro, mais cooling DIY et drivers data center.
- Tesla V100 32 Go sur AliExpress (~350 €) : le vrai bon plan VRAM/prix du moment, mais c’est réservé aux bricoleurs. Voir l’encadré dédié plus bas, parce qu’il y a un piège électrique sérieux.
- Jetson Orin Nano (~350 €) : si tu veux un truc qui consomme 7 W et tourne en permanence. Attention, le prix a fortement grimpé ces derniers mois, ce n’est plus le kit à 99 $ avant.
À ce niveau, ne rêve pas de génération d’image lourde ni de 32B. C’est un terrain de jeu, pas une station de prod.
400 – 900 €

Le sweet spot pour débuter sérieusement. 16 Go de VRAM ou un mini-PC milieu de gamme.
- RTX 4060 Ti 16 Go ou RX 7600 XT 16 Go : 7–13B confortables et de l’image raisonnable (SDXL, Flux en presets corrects).
- Tesla T4 16 Go : 70 W, excellente en perf/watt, parfaite pour un serveur d’inférence allumé H24.
- Mini-PC Ryzen AI 32 Go : polyvalent, basse conso, mais attention au support GPU sous Linux (j’y reviens plus bas).
900 – 1 800 €

Là, tu passes en 24 Go et tu peux faire du ComfyUI sérieux + du 32B. C’est la tranche des GPU 24 Go d’occasion, et clairement la plus rentable.
- RTX 3090 24 Go d’occasion (700–1 000 €) : LE meilleur achat, toutes catégories confondues. 24 Go, ~936 Go/s, compatibilité parfaite. Le neuf ne sert à rien ici, prends de l’occasion. Si tu ne devais retenir qu’une carte, c’est elle.
- RTX 4090 24 Go d’occasion (1 000–1 100 €) : même VRAM que la 3090 mais plus de patate, notamment en image. Là aussi le neuf est inutile.
- Tesla P100 32 Go : encore plus de VRAM pour pas cher, mais idle médiocre (voir section conso).
- Mini-PC à mémoire unifiée 64 Go type Minisforum AI X1 Pro (~1 100 $) : tu charges des modèles jusqu’à ~50B en Q4 sans GPU dédié. Le piège : ~120 Go/s de bande passante, donc compte 15–25 tok/s sur un Qwen 14B Q4. C’est lent mais ça tient en RAM ce qu’un GPU 24 Go ne tiendra jamais.
1 800 – 3 000 €

La tranche de la mémoire unifiée compacte et de l’edge costaud. Beaucoup de mémoire, faible conso, format de bureau, mais on troque la vitesse des gros GPU contre la capacité.
- Beelink SER9 (HX-370, ~2 300 €) : mini-PC Ryzen AI, basse conso (~7–9 W idle).
- Minisforum Strix Halo 64 Go (~2 300 €) : le modèle 128 Go n’est toujours pas dispo, on est cantonné au 64 Go pour l’instant. TDP modulable 45–120 W.
- Mac mini M4 64 Go (~2 800 €) : 70B quantifiés accessibles, idle dérisoire (~4–8 W), perf/watt imbattable. L’option la plus propre pour un nœud LLM always-on costaud.
- Jetson AGX Orin 64 Go (~2 400 € avec boîtier) : si tu fais de l’edge sérieux ou du RAG embarqué.
Plus de 3 000 €

Le haut du panier. C’est là que le 70B confortable, le 120B en 4-bit et l’image lourde deviennent vraiment fluides, mais le ticket d’entrée fait mal.
- RTX 5090 32 Go (3 500–5 000 €) : la puissance brute. 32 Go GDDR7, ~575 W rien que pour la carte. Réserve-la si tu fais de l’image lourde ou du training.
- Mac Studio M4 (à partir de ~4 400 € selon config) : jusqu’à 192 Go unifiée, 70B quantifiés + vidéo + IA, idle ridicule. Le compromis perf/watt le plus propre pour une station.
- DGX Spark (~5 000 €) : 128 Go unifiée (GB10), écosystème CUDA natif dans un format de bureau.
- Multi-GPU 4× 3090 en rack : 96 Go de VRAM totale pour qui veut du 70B+ sans compromis. C’est plus un labo qu’une machine perso, et la facture électrique suit (voir plus bas).
Le prix de la mémoire : la variable qui va tout chambouler
Tous les prix ci-dessus sont une photo à l’instant T, et cette photo va se dégrader. On a passé l’article à répéter que tu achètes de la mémoire avant tout : il faut donc parler du fait que la mémoire est en pleine crise de prix.
Depuis fin 2025, la DRAM et la NAND flambent. Les tarifs ont été multipliés par 3 à 4 en moins d’un an. La cause tient en trois lettres : la HBM, cette mémoire ultra-rapide qui équipe les accélérateurs IA des data centers (NVIDIA H100/H200/B200, AMD MI300…). Les trois seuls fabricants mondiaux (Samsung, SK Hynix, Micron) ont réorienté leurs capacités vers cette HBM à forte marge, au détriment de la DDR4, DDR5, LPDDR5 et de la NAND grand public. Résultat : moins d’offre, des stocks tendus, des prix qui s’envolent. Et ça ne s’arrête pas à la RAM système : la GDDR des cartes graphiques est touchée par le même effet, donc les GPU sont aussi concernés.
Et ce n’est pas fini. Micron annonce +50 à 60 % sur la DRAM dès le premier trimestre 2026, TrendForce table sur +58 à 63 % de plus au deuxième trimestre. Pour résorber la pénurie, il faudrait augmenter la production de 12 % par an d’ici 2027 ; les plans industriels actuels ne prévoient que 7,5 %. L’écart ne se comble pas par magie : une nouvelle usine de semi-conducteurs met des années à monter en cadence. Les prévisions convergent vers une tension qui dure au moins jusqu’en 2027, avec un plateau des prix cette année-là et une éventuelle détente seulement à partir de 2028. Les plus pessimistes (Counterpoint) évoquent 2030.
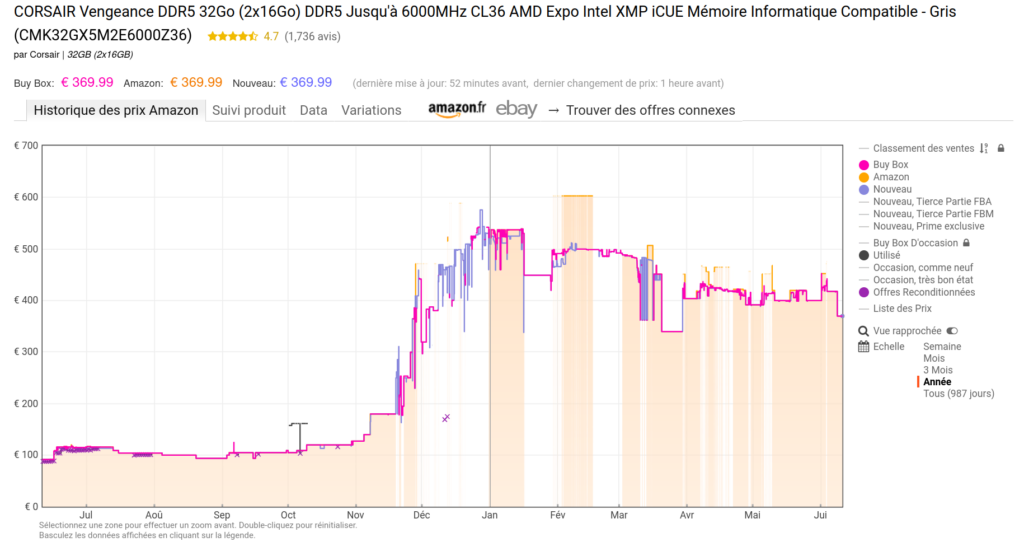
Donc oui, il y a eu de légères respirations sur certains tarifs, mais la tendance de fond est haussière, et elle va le rester un moment. Ça a deux conséquences très concrètes pour toi.
D’abord, les configs gourmandes en mémoire vont coûter de plus en plus cher. Un mini-PC 128 Go de mémoire unifiée ou une carte à grosse VRAM, c’est exactement ce que le marché s’arrache. Si ton projet en dépend, le surcoût ne fera que grimper.
Ensuite, et c’est là que je vais à contre-courant du discours ambiant : dans pas mal de cas, le calcul honnête, c’est de ne pas acheter maintenant. À ces prix-là, monter une vraie config locale revient cher, et on sait que la mémoire restera tendue jusqu’en 2027-2028. Une stratégie tout à fait défendable, c’est donc : j’attends deux ans que le marché se détende, et en attendant j’utilise les API. Tu paies au token sur la période, mais tu n’immobilises pas 3 000 ou 5 000 € dans une machine achetée au pic, qui aura perdu de la valeur quand les prix mémoire seront retombés. Pour un usage modéré, l’addition API sur deux ans peut largement rester sous le coût d’achat + électricité d’une grosse config.
Si malgré tout tu veux du local tout de suite, l’occasion est ta meilleure protection. Une RTX 3090 ou 4090 d’occasion, avec sa VRAM déjà soudée et payée au prix d’hier, te met à l’abri de la flambée. C’est l’arbitrage à faire : soit tu passes par l’occasion maintenant, soit tu encaisses le coût API quelque temps et tu investis quand le marché aura soufflé. Ce qui n’a pas de sens, c’est d’acheter du neuf gourmand en mémoire en plein pic.
Dernier point à connaître : à partir de 2026, la disponibilité risque de devenir un problème avant même le prix. Si tu choisis la voie « j’achète maintenant », garde en tête que trouver le composant pourra être plus compliqué que le payer.
Inférence vs diffusion : ce que ça change
On mélange trop souvent les deux usages, alors qu’ils ne sollicitent pas le matériel pareil.
Inférence LLM. C’est dominé par la bande passante mémoire. Le modèle doit être lu en entier à chaque token généré. D’où l’importance de la VRAM (pour faire rentrer le modèle) ET de la bande passante (pour le lire vite). Une P100 à 16 Go fera tourner un 32B Q4, mais ses ~550 Go/s la rendent plus lente qu’une 3090.
Diffusion / génération d’image. Là, l’architecture du GPU compte davantage. Les Tensor Cores modernes (FP8, etc.) accélèrent énormément. C’est pour ça qu’une Pascal (P100) fait tourner ComfyUI mais reste sensiblement plus lente qu’une 3090/4090/5090 sur le même workflow. En image, l’ancienneté de l’archi se paie cash.
Conclusion pratique : si ton truc c’est le LLM, optimise la mémoire et la bande passante. Si c’est l’image, oriente-toi vers une archi récente (Ampere minimum, idéalement Ada/Blackwell).
La consommation : le truc que personne ne regarde
C’est l’angle mort des tableaux VRAM/prix. Si ta machine tourne H24 pour Ollama, n8n ou ComfyUI, deux chiffres comptent : la conso idle (machine allumée, modèle pas chargé) et la conso en calcul.
Attention, point crucial : les chiffres ci-dessous sont pour la carte seule. C’est toute la config qui consomme. CPU, carte mère, RAM, ventilation, alim avec son rendement : ajoute facilement 100 à 250 W sous charge par-dessus le GPU. Une config autour d’une RTX 5090 dépasse le plus souvent 1 000 W à pleine charge. Donc quand tu lis « 575 W » pour la 5090, lis plutôt « 1 000 W au mur » pour la machine complète.
| GPU (carte seule) | Mémoire | Idle | Calcul | Verdict 24/7 |
|---|---|---|---|---|
| Tesla T4 | 16 Go | ~36 W | ~70–75 W | Excellent serveur sobre |
| Tesla P100 | 16 Go | ~25–30 W | ~250 W | Bricolable, idle moyen |
| Tesla V100 | 16–32 Go | ~40–50 W | ~250 W | Puissant, mauvaise veille |
| RTX 3090 | 24 Go | ~10–30 W | ~350 W | Bon ratio polyvalent |
| RTX 4090 | 24 Go | ~4–29 W | ~450–480 W | Fort, lourd en charge |
| RTX 5090 | 32 Go | ~45–100 W | ~575 W | Config complète >1 000 W |
| Jetson Orin Nano | 8 Go | ~2,5–7 W | ~7–15 W | Top edge always-on |
| Jetson AGX Orin | 64 Go | ~15–20 W | ~30–60 W | Bon compromis edge costaud |
Côté boîtiers compacts, l’intérêt c’est que les chiffres sont système complet (pas de tour à ajouter autour) :
| Plateforme (système complet) | Mémoire | Idle | Charge |
|---|---|---|---|
| Mac mini M4 | 16–64 Go | ~4–8 W | ~30–40 W |
| Mac Studio M4 | 36–192 Go | ~6–10 W | ~170–220 W |
| DGX Spark | 128 Go | ~22–25 W | ~240 W (max système) |
| Beelink SER9 (HX-370) | 32–64 Go | ~7–9 W | ~78 W |
| Minisforum Strix Halo (Ryzen AI Max+ 395) | jusqu’à 128 Go | ~9–12 W | ~120 W |
C’est aussi là que les boîtiers compacts à mémoire unifiée prennent leur revanche sur les gros GPU : un Mac mini ou un Strix Halo te fait tourner un 70B en consommant ce qu’une tour avec 5090 brûle au repos. Si ton usage c’est l’always-on, le perf/watt écrase la perf brute.
Le truc à retenir, qui n’apparaît jamais dans un tableau prix/VRAM : une P100 ou une V100 est souvent bloquée en état de perf élevé au repos, donc son idle est mauvais. Géniale pour bricoler et calculer, beaucoup moins pour un serveur domestique qui passe sa vie à attendre. Ça se rattrape sous Linux en réglant les p-states (voir l’astuce dans l’encadré V100 plus bas), mais c’est un réglage à faire, ce n’est pas automatique. À l’inverse, une T4, un Jetson ou un Mac mini sont imbattables pour de l’always-on sans rien toucher.
Règle simple de lecture :
- Tu calcules souvent : 3090/4090/5090, peu importe l’idle.
- Tu veux un nœud IA allumé toute la journée : Mac mini, Jetson, T4. La sobriété prime.
Rien n’est gratuit : la facture, en vrai
Petite parenthèse vécue, parce que c’est facile de raisonner en watts sans jamais regarder la note. Voici ma conso réelle sur 12 mois (relevé fournisseur, en € par mois) :
| Mois | € | Mois | € |
|---|---|---|---|
| Juil. 2025 | 86 | Janv. 2026 | 215 |
| Août 2025 | 92 | Févr. 2026 | 209 |
| Sept. 2025 | 97 | Mars 2026 | 193 |
| Oct. 2025 | 116 | Avr. 2026 | 164 |
| Nov. 2025 | 149 | Mai 2026 | 86 |
| Déc. 2025 | 195 | Total | ~1 601 |
J’ai commencé à utiliser ma 5070 mi-octobre, et la courbe grimpe à partir de là. En mai, je suis passé sur des API pour une partie du travail, et la facture retombe à 86 €, exactement le niveau d’avant la 5070.
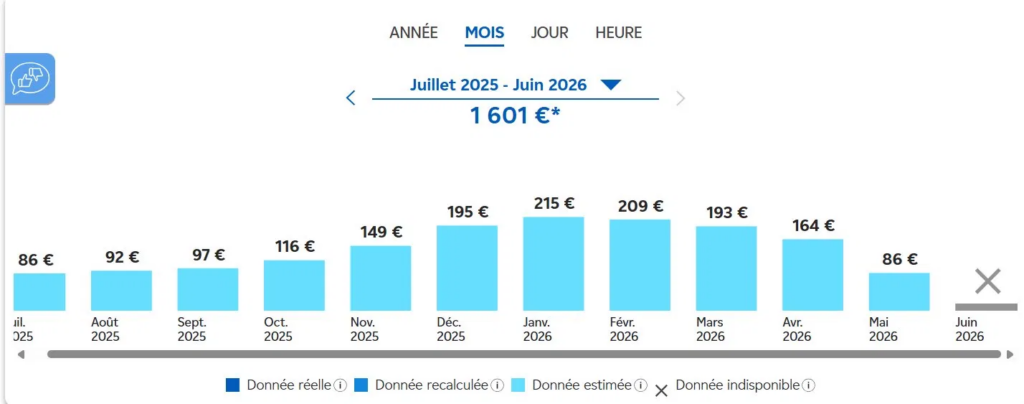
Et là, pas d’échappatoire : je me chauffe au bois :D. Le pic hivernal n’est donc pas un artefact du chauffage électrique. Le seul gros changement sur la période, c’est la machine qui s’est mise à tourner pour faire de l’IA. La corrélation est limpide : GPU allumé mi-octobre, la facture décolle ; bascule sur API en mai, elle redescend à son niveau de départ. Il reste bien quelques variations saisonnières mineures (éclairage, jours plus courts), mais elles ne pèsent pas 100 € par mois. Le coupable, c’est le calcul local.
Mais le message de fond tient : rien n’est gratuit. La machine locale a un coût électrique réel et récurrent, et l’API a un coût au token. L’IA locale n’est pas « gratuite » par opposition au cloud : tu déplaces juste la dépense de la facture API vers la facture EDF. À toi de voir laquelle correspond à ton usage et à ton volume.
Encadré bricoleur : la Tesla V100 32 Go (~350 €)

C’est le meilleur ratio VRAM/prix du moment, mais ça se mérite. Avant de cliquer sur AliExpress, tu dois savoir trois choses :
- L’alimentation est piégeuse. Le connecteur n’est pas un PCIe standard, il y a une modif/adaptateur à faire. Mal branchée, tu risques de cramer la carte mère. Les adaptateurs se trouvent en ligne, mais c’est une manip à ne pas rater.
- Ventilation passive. Comme toutes les cartes data center, pas de ventilo intégré. Il faut ajouter un shroud + ventilateur sinon ça monte en température.
- Idle à programmer sous Linux. Par défaut elle reste bloquée en état de perf élevé (P0), donc elle tire 40 W et plus au repos pour ne rien faire. Sans réglage des p-states, ton idle est catastrophique pour du 24/7.
Astuce : dompter les p-states. Le problème touche toutes les cartes data center (P100, V100, T4…) : par défaut elles ne redescendent pas en basse conso au repos. Deux approches.
D’abord, active le persistence mode pour fiabiliser le comportement des clocks :
bash
sudo nvidia-smi -pm 1Ensuite, le plus simple et le plus propre : le démon nvidia-pstated (open-source, dispo sur GitHub). Il surveille l’utilisation du GPU et force la carte en p-state bas (P8) dès qu’elle est inactive, puis la repasse en P0 sous charge, automatiquement, sans bricoler tes clocks à la main. Sur une P100/V100, ça fait tomber l’idle de ~40 W à une dizaine de watts. Tu le lances en service systemd et tu n’y penses plus.
Alternative manuelle si tu veux verrouiller les fréquences toi-même (nvidia-smi -lgc), mais tu plafonnes alors les perfs et c’est moins souple que le démon. Pour un serveur allumé en permanence, nvidia-pstated est de loin la meilleure option : c’est lui qui transforme une carte « mauvais idle » en carte 24/7 acceptable.
En clair : 350 € pour 32 Go, c’est imbattable, mais c’est un projet Linux à part entière, pas un achat plug-and-play. Si tu n’es pas à l’aise avec le tuning matériel, reste sur une 3090 d’occasion.
Compatibilité : le piège PyTorch / CUDA
C’est là que beaucoup se font avoir. Avoir 64 Go de mémoire unifiée ne sert à rien si ta stack logicielle ne sait pas l’exploiter au GPU. Petit tour par écosystème.
NVIDIA / CUDA. Le standard de fait. PyTorch, vLLM, Ollama, ComfyUI : sur de l’Ampere ou de l’Ada (3090, 4090…), tout marche nativement, builds officiels, zéro galère. C’est la raison numéro un pour rester sur du NVIDIA si tu fais du dev ou du training, pas juste de l’inférence.
Sauf qu’il y a une grosse exception, et elle est contre-intuitive : la série RTX 5000 (Blackwell) est aujourd’hui le moins bon choix CUDA. Ces cartes utilisent une nouvelle compute capability, sm_120, et les versions stables de PyTorch ne sont compilées que jusqu’à sm_90 (Hopper). Concrètement, sur une 5070 / 5080 / 5090 fraîchement montée, tu te prends souvent un CUDA error: no kernel image is available for execution on the device, ou pire, un fallback silencieux sur le CPU. Le seul moyen d’en tirer quelque chose, c’est de passer par les builds nightly (cu128/cu129, Python 3.13 conseillé) ou de compiler PyTorch depuis les sources. Ça fonctionne, mais ce n’est pas une version stable définitive.
Et ça dure. La série 50 est sortie début 2025 ; on est mi-2026 et le support officiel de sm_120 dans le PyTorch stable n’est toujours pas là. Les demandes côté PyTorch (dont une qui cite nommément la 5070 Ti) sont encore ouvertes. Plus d’un an à bricoler du nightly pour faire tourner une carte vendue, entre autres, pour l’IA : c’est le monde à l’envers. Et le plus cocasse, c’est qu’on parle déjà de la suite : les fuites (Kopite7kimi, relayé par Wccftech) annoncent une génération RTX 60 sous architecture Rubin pour le second semestre 2027. Autrement dit, NVIDIA prépare déjà la relève alors que la génération actuelle n’est toujours pas correctement prise en charge par la stack logicielle. Bref, si tu veux du NVIDIA sans prise de tête logicielle, une 3090 ou 4090 d’occasion t’évitera ces galères ; la 5090 ne se justifie que si tu as vraiment besoin de sa puissance brute et que le tuning logiciel ne te fait pas peur.
AMD / ROCm. Sur les gros GPU AMD dédiés, ROCm progresse et PyTorch a ses builds. Mais sur les iGPU Ryzen AI récents (Strix Halo compris), le support ROCm reste partiel en 2026. Ollama tourne très bien en CPU+RAM, mais sans accélération GPU complète. Donc le mini-PC AMD 64 Go que tu lorgnes : il chargera de gros modèles, mais souvent en s’appuyant sur le CPU. À garder en tête avant d’acheter.
Apple / Metal / MLX. PyTorch a un backend MPS qui fonctionne, mais tous les ops ne sont pas couverts. Pour Apple Silicon, le vrai chemin c’est MLX (le framework d’Apple) ou Ollama/llama.cpp. La bonne nouvelle : la grosse bande passante mémoire (273 Go/s sur M4 Pro) compense, et le perf/watt est excellent.
Pascal (P100/V100). CUDA-capable, donc Ollama/vLLM/ComfyUI tournent. Mais c’est de l’archi ancienne : pas de FP8, pas de Tensor Cores modernes, et il faut surveiller que les versions récentes de PyTorch ne lâchent pas le support des vieilles compute capabilities (sm_60/sm_70). Plus les drivers data center (pas GeForce) et le cooling DIY. C’est jouable, mais ce n’est clairement pas plug-and-play.
Jetson. Écosystème Linux embarqué (JetPack), pas Windows. CUDA présent mais parfois plus limité que sur GPU desktop côté bibliothèques. Parfait pour de l’edge, pas pour reproduire ta station de dev.
En résumé : quel matériel pour quel besoin
- Découvrir, RAG léger, 7B, petit budget. RTX 3060 12 Go d’occasion, ou une Tesla P4/T4 si tu acceptes le bricolage. T4 si c’est pour du H24 sobre. Et si tu es à l’aise avec le tuning matériel, la V100 32 Go à ~350 € est imbattable en VRAM/prix.
- Bosser sérieusement, 32B, ComfyUI, le meilleur rapport qualité/prix. La RTX 3090 24 Go d’occasion (700–1 000 €). Sans hésiter. CUDA natif, 24 Go, bande passante correcte. Le neuf ne sert à rien.
- Charger de gros modèles 70B sans exploser le budget GPU. Un mini-PC à mémoire unifiée 64–128 Go (Minisforum, Strix Halo, ~2 300 €). En acceptant la lenteur et le support GPU partiel sous Linux.
- Nœud IA allumé en permanence, basse conso. Mac mini M4 (~2 800 € en 64 Go) ou Jetson. Conso de N100, moteur IA en plus.
- 70B confortable, perf/watt propre, format bureau. Mac Studio M4 (~4 400 €) ou DGX Spark (~5 000 €), si le budget suit.
- Image lourde, puissance brute, training. RTX 4090 d’occasion (~1 000–1 100 €) ou 5090 (3 500–5 000 €), archi récente obligatoire, sans oublier que la config 5090 complète tape dans les 1 000 W.
Le bon réflexe : pars de ton usage réel (inférence ? image ? always-on ?), déduis la mémoire dont tu as besoin, vérifie que ta stack supporte le matériel au GPU, et seulement après regarde le prix. Dans cet ordre. La machine la plus tape-à-l’œil sur le papier n’est pas forcément celle qui tournera le mieux chez toi.
Et garde en tête les deux factures et le calendrier. À l’achat, la mémoire est en pleine flambée et la tendance reste haussière jusqu’en 2027-2028 : à ces prix-là, le calcul le plus malin n’est pas forcément d’acheter aujourd’hui. Pour beaucoup, attendre deux ans que le marché se détende et tenir avec les API entre-temps coûte moins cher que d’immobiliser plusieurs milliers d’euros dans une machine achetée au pic. Si tu veux quand même du local maintenant, passe par l’occasion, pas par du neuf gourmand en mémoire. En consommation, un GPU qui tourne, c’est une centaine d’euros par mois sur ta facture, chiffre réel à l’appui. L’IA en local n’est pas gratuite. Elle peut valoir largement le coup, mais en connaissance de cause, les deux factures posées sur la table, et parfois la meilleure décision c’est juste d’attendre.
Aucun mot sur les B50/B70 ?
Touché, le B70 manque. Je l’avais écarté parce que la stack Intel n’était pas mûre au moment où j’ai écrit, mais sur le papier c’est le meilleur candidat VRAM/€ côté carte neuve en 2026 : 32 Go pour ~900 €, 608 Go/s, et jusqu’à 4 cartes pour 128 Go. Plus de VRAM qu’une 3090 d’occasion, mais moins de bande passante (608 contre 936 Go/s). Le vrai frein est logiciel : le backend vLLM XPU ne sert que du FP16 aujourd’hui (bfloat16 bloqué, donc Gemma 2 ne passe pas), et le reste demande de bricoler les conteneurs. Exactement le piège que je décris pour ROCm, version Intel. J’ajoute un paragraphe, merci pour le rappel.
Très belle synthèse Bravo. (j’ai bricolé des V100 et je suis très content, j’ai limité la puissance en veille mais aussi en charge sans que ça ne dégrade vraiment les token/sec)
Pour la conso électrique regarde du coté de ton chauffe eau, s’il est électrique et dans ton garage, c’est sûrement lui le gros consommateur. Chez moi, aussi chauffé au bois, le chauffe eau représente 70% de ma consommation électrique.
Merci Thom ! Bon retour sur les V100 : limiter la puissance en charge sans perdre en token/sec, c’est logique vu qu’en inférence le GPU attend surtout sa mémoire. Je le note pour compléter l’encadré.
Pour le chauffe-eau, la piste est bonne dans l’absolu, mais elle n’explique pas ma courbe : un chauffe-eau consomme de façon constante toute l’année, alors que ma facture décolle pile à la mise en route de la 5070 Ti et retombe pile quand je bascule sur les API. Le motif colle au GPU, pas à un poste fixe.
A bientôt Louis 🐇 🤜 🤛 🐰
Tu n’abordes pas les cartes graphiques « gamer » AMD.
C’est l’alternative pour les personnes polyvalentes (jeux et expériences ML locales) qui ne sont pas prêtes à mettre le prix dans une carte graphique NVIDIA.
Dilem idem que pour la stack Intel (moins de bande passante pour plus de VRAM). Je sais que le support ROCm est meilleur que pour Intel pour les cartes hautes gammes, mais je n’en sais pas plus.
Hello ache,
Remarque juste, et je vais y répondre en deux temps, parce que ton cas d’usage (polyvalent jeux + ML) est différent de celui de l’article.
Sur les cartes gamer AMD d’abord. Si tu es joueur avant tout et que tu bidouilles du ML à côté, une 9070 XT se défend, je ne vais pas te dire le contraire. Le support ROCm sur RDNA 4 est réel : Ollama, llama.cpp et ComfyUI tournent, et c’est effectivement mieux que la stack Intel aujourd’hui. Mais je nuance ton parallèle avec le dilemme Intel : le B70 échange de la bande passante contre 32 Go de VRAM à 900 €. Les Radeon gamer, elles, n’offrent même pas ce troc. Une 9070 XT plafonne à 16 Go, exactement comme sa concurrente NVIDIA, avec un écosystème logiciel en retrait. Tu ne gagnes rien côté IA, tu perds CUDA. C’est pour ça qu’elles ne sont pas dans le dossier : elles n’apportent aucun arbitrage nouveau, juste une case en moins.
Deuxième temps, et c’est là que ça devient intéressant : AMD a une vraie réponse IA, mais ce n’est pas dans la gamme gamer. C’est la Radeon AI PRO R9700 : le silicium de la 9070 XT, mais avec 32 Go de GDDR6, 644 Go/s de bande passante, ROCm supporté officiellement et une conception blower pensée pour empiler jusqu’à 4 cartes (128 Go de VRAM dans une tour). Sur le papier, c’est LA carte AMD pour l’IA locale.
Le hic, c’est le prix. Annoncée à 1 299 €, elle se négocie plutôt entre 1 400 et 1 550 € en ce moment. À ce tarif, elle se retrouve face à la 3090 d’occasion : 24 Go, une bande passante supérieure (936 Go/s), CUDA, pour 700 à 1 000 €. Un acheteur LDLC qui a remplacé sa 3090 par une R9700 le résume bien : ça marche avec Ollama, mais ROCm demande beaucoup plus de manipulations que CUDA. Les 8 Go de VRAM supplémentaires ne compensent pas encore l’écart de prix et l’écart d’écosystème.
Bref : la R9700 est la première carte AMD que je surveille sérieusement pour l’IA locale. Si elle passe sous les 1 100 € et que ROCm continue de progresser au rythme actuel, elle gagnera sa ligne dans la prochaine mise à jour du dossier. Aujourd’hui, elle reste un cran trop chère face à l’occasion NVIDIA.
A bientôt Louis 🐇 🤜 🤛 🐰
Vous ne parlez pas du Beelink GTR9 pro ?
Hello Raphael,
Bonne question. Je n’en ai pas parlé pour deux raisons.
La première : le GTR9 Pro est un clone Strix Halo parmi une douzaine d’autres (GMKtec EVO-X2, Framework Desktop, HP Z2 Mini, Geekom A9 Mega…). Même Ryzen AI Max+ 395, mêmes 128 Go de LPDDR5X-8000, même bande passante d’environ 256 Go/s, mêmes limites ROCm sur l’iGPU. La catégorie « mini-PC à mémoire unifiée » du dossier le couvre déjà. Seuls changent le châssis, le bruit et le SAV.
La seconde, c’est le prix. Au moment où j’écris, il s’affiche à plus de 3 300 € en France. À ce tarif, un ASUS Ascent GX10 se trouve autour de 3 500 € avec la même quantité de mémoire unifiée (128 Go), une bande passante équivalente (273 Go/s), mais surtout CUDA natif : PyTorch, vLLM, TensorRT, ComfyUI, tout tourne sans bricolage, avec les Tensor Cores Blackwell derrière pour le prompt processing et le fine-tuning. Côté Strix Halo, dès que tu sors de l’inférence Ollama, tu retombes dans le piège ROCm décrit dans l’article. Le GTR9 Pro traîne en plus un bug documenté sur ses ports 10 GbE qui plantent sous forte charge GPU.
Bref : à 200 € d’écart, entre un Strix Halo et une machine CUDA, le choix est vite fait. Et si le budget est plus serré, la 3090 d’occasion à 700-1 000 € reste la meilleure porte d’entrée si tes modèles tiennent en 24 Go.
A bientôt Louis 🐇 🤜 🤛 🐰
Bonjour/Bonsoir ,
Serait-il possible d’avoir également une comparaison avec les derniers modèles AMD (9060, 9070 XT) sur le marché ?
Hello Bastien,
Bonne question, et la réponse est volontaire : je ne les ai pas mises parce que ce ne sont pas des cartes pensées pour l’IA, et que les acheter pour ça, c’est du gâchis de watts et d’euros.
Je détaille. Une 9060 XT 16 Go tourne autour de 440-510 € en ce moment. Une 9070 XT 16 Go, comptez encore plusieurs centaines d’euros de plus. Pour de l’IA locale, ces cartes cumulent trois handicaps :
16 Go de VRAM maximum. C’est le même plafond que ma 5070 Ti : tu es limité aux modèles 7B-14B confortables, et tu quantifies agressivement au-delà. Aucun avantage sur NVIDIA à ce niveau.
Pas de CUDA. Le support ROCm sur RDNA 4 a progressé, Ollama et llama.cpp tournent, ComfyUI aussi. Mais tout le reste de l’écosystème (une grosse partie des nodes ComfyUI, les outils de fine-tuning, la moitié des projets GitHub que tu voudras tester) est écrit pour CUDA d’abord. Tu passeras ton temps à contourner, quand ça ne bloque pas tout court. C’est le piège que je décris dans l’article avec ROCm : ça marche sur les sentiers battus, ça coince dès que tu en sors.
Le rendement par watt et par euro. À prix équivalent, une RTX 5060 Ti 16 Go fait le même travail avec l’écosystème complet. Et surtout, pour le prix d’une 9070 XT, tu touches une RTX 3090 24 Go d’occasion : 50 % de VRAM en plus, une bande passante mémoire supérieure (936 Go/s contre 645), et CUDA. Pour de l’IA, il n’y a pas match.
Soyons clairs sur la nuance : si tu as déjà une 9060 ou 9070 XT dans ton PC gaming et que tu veux faire tourner un modèle de temps en temps, vas-y, ça passe via ROCm ou Vulkan. Mais monter une config IA autour de ces cartes en 2026, non. Ce sont d’excellentes cartes de jeu, c’est leur métier, et il faut le leur laisser.
A bientôt Louis 🐇 🤜 🤛 🐰