
Cet article fait suite à la Partie 2 : Passer sous Linux pour libérer votre GPU.
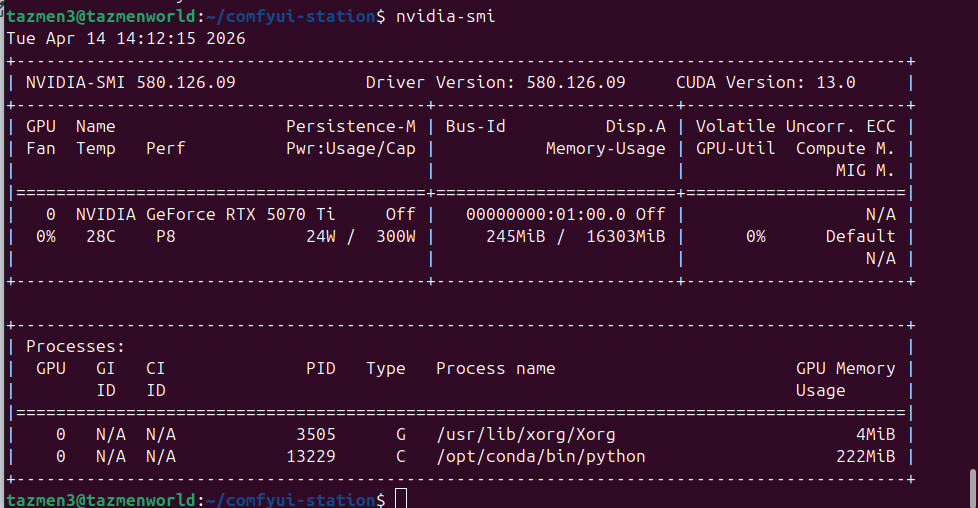
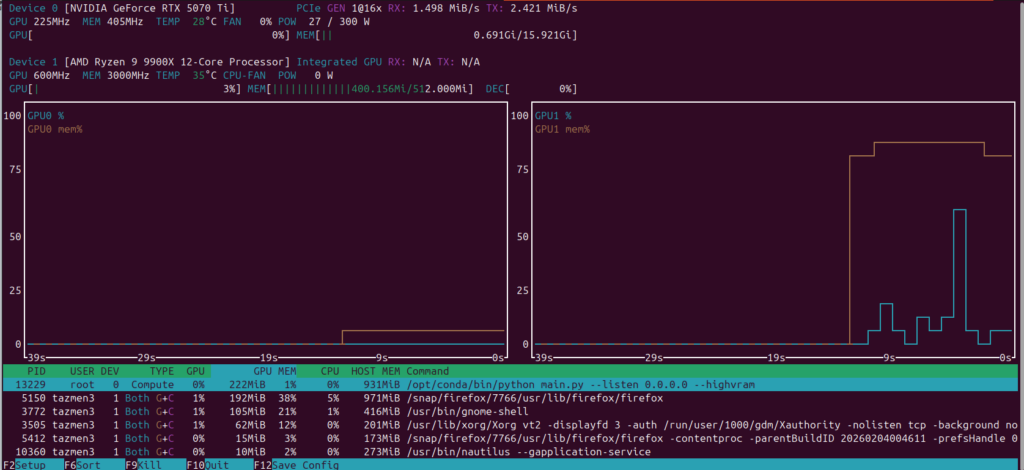
Maintenant que le système est propre, que l’interface graphique ne vient plus grignoter vos précieux gigaoctets de mémoire vidéo, on va s’attaquer au « cerveau » de la machine. L’idée ici n’est pas de suivre un tuto de plus sur l’IA, mais de comprendre comment orchestrer une stack qui tient la route pour de la production réelle.
Reprendre le contrôle : mon IA locale avec Mistral NeMo, Ollama et Open WebUI
Le passage à une IA 100 % locale n’est pas qu’une question de confidentialité. C’est avant tout une question de confort et de précision. Quand on travaille sur des projets sérieux, on ne peut pas se permettre d’avoir une IA qui « oublie » le début de la conversation ou qui répond avec le ton policé d’un département de relations publiques californien.
Voici comment j’ai structuré mon environnement pour exploiter au maximum mes 16 Go de VRAM.
1. Pourquoi le choix « Européen » : Mistral vs Llama vs Qwen
C’est un point crucial qu’on aborde rarement. Tous les modèles d’IA ne se valent pas, et ce n’est pas qu’une question de « benchmarks ». C’est une question de culture et de structure de langue.
- Llama (Meta) : Très puissant, mais formaté par une vision américaine de la « safety ». Le modèle a tendance à être trop verbeux, à s’excuser pour un rien et à utiliser des tournures de phrases très (trop) amicales qui sonnent faux en français comme Gemini ou Chatgpt.
- Qwen (Alibaba) : Techniquement impressionnant, surtout en code, mais on sent parfois une structure de pensée différente, presque « traduite », qui peut manquer de naturel sur des nuances rédactionnelles complexes en Europe.
- Mistral (Mistral AI) : C’est mon choix par défaut. Pourquoi ? Parce que Mistral est conçu en Europe. On retrouve dans ses réponses une structure logique et une concision qui collent beaucoup mieux à notre façon de nous exprimer. Le ton est plus direct, plus pragmatique, et surtout, il maîtrise les subtilités de la langue française (et européenne en général) sans avoir besoin d’en faire des tonnes. C’est un modèle qui « réfléchit » de manière plus proche de la nôtre.
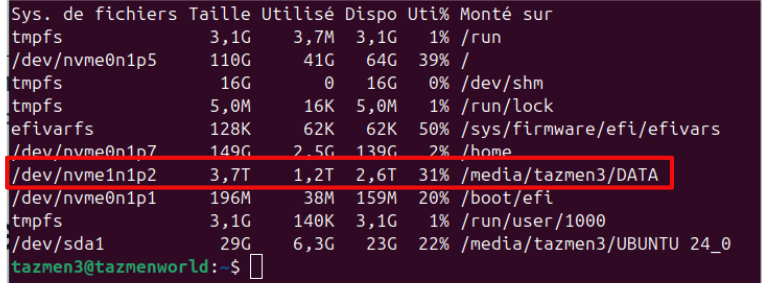
2. La stratégie de stockage : Le NVMe de 4 To dédié
On en a parlé rapidement, mais le stockage est le moteur silencieux de votre IA. Charger un modèle de 14 Go doit être une opération transparente.
J’utilise un disque NVMe de 4 To entièrement dédié à l’IA. Voici pourquoi c’est un choix pragmatique :
- Éviter l’asphyxie du système : Les modèles sont lourds. Si vous téléchargez trois ou quatre versions de Mistral ou de Codestral pour comparer, vous perdez 50 Go en dix minutes. Sur un disque système, c’est le crash assuré.
- Vitesse de swap : Même avec 16 Go de VRAM, il arrive qu’on ait besoin de charger/décharger des modèles pour passer du texte à l’image. Le NVMe permet de le faire sans avoir l’impression que le PC a figé.
- Anonymisation des chemins : Pour Docker, j’ai monté ce disque sur un point propre (type
/mnt/storage-ia/). Cela permet de garder un fichier de configuration lisible et de déplacer l’intégralité de sa bibliothèque de modèles d’une machine à l’autre simplement en déplaçant le disque et en mettant à jour une ligne dans le.env.
3. L’architecture Docker : Le pilotage de la VRAM
Docker est indispensable pour isoler les pilotes NVIDIA. Sans lui, une mise à jour d’Ubuntu peut casser votre installation CUDA. Voici la structure de mon docker-compose.yml. Notez bien la gestion de ComfyUI : il est là, mais il ne démarre que si je l’appelle.
services:
# Moteur d'inférence (Le coeur)
ollama:
image: ollama/ollama
container_name: ollama
volumes:
- /chemin/anonymise/ssd-ia/models:/root/.ollama
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
restart: unless-stopped
# Interface utilisateur (Le visage)
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
volumes:
- ./open-webui-data:/app/backend/data
depends_on:
- ollama
ports:
- "3000:8080"
environment:
- 'OLLAMA_BASE_URL=http://ollama:11434'
restart: unless-stopped
# Génération d'images (Démarrage manuel pour préserver les 16 Go de VRAM)
comfyui:
build: .
container_name: comfyui
runtime: nvidia
restart: "no" # <--- Crucial : ne consomme rien au repos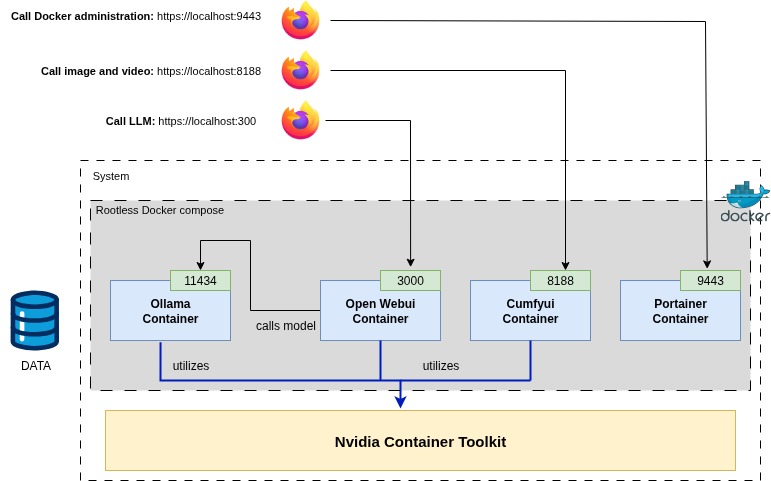
4. Tableau comparatif des modèles utilisés
Voici comment je répartis la charge de travail sur ma carte de 16 Go. L’idée est d’avoir le bon outil pour la bonne tâche, sans jamais saturer la mémoire inutilement.
| Modèle | Taille | Usage Principal | Pourquoi ce choix ? | Occupation VRAM (Q8) |
|---|---|---|---|---|
| Mistral NeMo 12B | 12B | Rédaction & Chat quotidien | Le plus naturel. Structure de phrase européenne, concis et intelligent. | ~13 Go |
| Ministral-3 14B | 14B | Analyse & Code complexe | Logique pure. Énorme contexte (256k) pour avaler des docs entiers. | ~15 Go |
| Llama 3.1 8B | 8B | Tâches de tri basiques | Rapidité. Utilisé quand la nuance importe peu mais que la vitesse est clé. | ~8 Go |
5. Pourquoi ces modèles et pas d’autres ?
Le choix de Mistral NeMo 12B est le résultat de nombreux tests. Sur une carte de 16 Go, c’est le « sweet spot ».
- En Q8_0 (8-bit) : Le modèle est quasi identique à la version non compressée. On a une précision chirurgicale.
- Le style : Contrairement à Llama qui a tendance à donner des conseils de vie non sollicités ou à faire de longs préambules (« En tant qu’intelligence artificielle, je… »), Mistral NeMo répond à la question. Point. C’est ce gain de temps et cette clarté qui font la différence en milieu pro.
Le Ministral-3 14B, lui, est mon joker pour les dossiers lourds. Sa capacité à gérer 256 000 tokens change la façon dont on travaille. On ne lui donne plus une question, on lui donne un contexte global. C’est le modèle que je sollicite pour auditer des fichiers de configuration Docker ou pour résumer des échanges techniques interminables.
6. Gestion du workflow : Priorité au texte
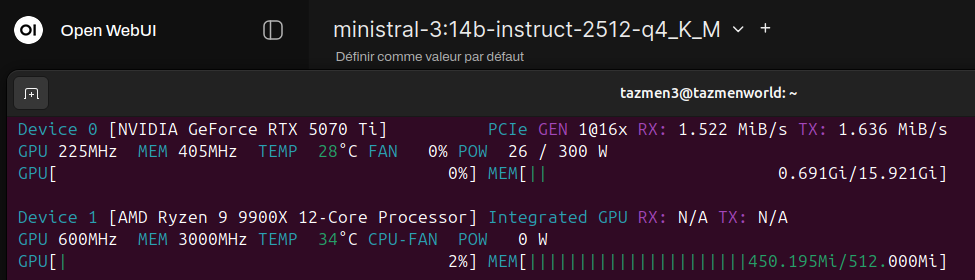
Dans ma configuration, la VRAM est une ressource précieuse qu’on ne gaspille pas. Le fait d’avoir mis ComfyUI (ou tout autre service d’image) en démarrage manuel est un choix pragmatique. Faire de l’image demande souvent de charger des modèles SDXL ou Flux qui prennent 10 à 12 Go de VRAM. Si Ollama a déjà réservé 13 Go pour Mistral, le crash est inévitable.
Mon workflow est donc linéaire :
Phase créative : Je coupe les modèles texte (Ollama libère la VRAM automatiquement après quelques minutes d’inactivité) et je lance ComfyUI.
Phase de réflexion/rédaction : 100 % de la VRAM pour Mistral via Open WebUI.
7. Vers une mémoire infinie : Le RAG (Prochainement)
Vous avez sans doute remarqué l’option « Documents » dans Open WebUI. C’est ce qu’on appelle le RAG (Retrieval-Augmented Generation). L’idée est simple : au lieu de tout demander au modèle, on lui permet de fouiller dans nos propres fichiers stockés sur le SSD de 4 To.
C’est un sujet tellement vaste et puissant (transformer son PC en base de connaissances souveraine) que j’ai décidé de lui consacrer un article entier. On y verra comment indexer des milliers de documents sans que cela ne ralentisse l’IA et comment poser des questions à sa propre archive technique.
Conclusion
Reprendre le contrôle de son IA, c’est d’abord arrêter de subir les choix des géants du cloud. Avec une carte de 16 Go, un bon disque NVMe et une stack Docker bien réglée, on a entre les mains un outil de travail plus performant et plus respectueux de notre culture que n’importe quel abonnement à 20$/mois.
Mistral NeMo et Ministral-3 ne sont pas juste des noms sur un benchmark, ce sont des outils calibrés pour notre façon de travailler en Europe. Optimisez votre VRAM, soignez votre stockage, et laissez l’IA bosser pour vous, pas l’inverse. 🚀🛠️
Note technique : Pour ceux qui veulent tester le Ministral-3 14B dès maintenant sur leur config Docker, la commande ollama run ministral-3:14b est votre point de départ.