
Si vous avez suivi les deux premiers articles, vous avez maintenant une bête de course sous Linux qui fait tourner Mistral Nemo au doigt et à l’œil grâce à Ollama. On a optimisé la VRAM, on a une interface WebUI qui n’a rien à envier à ChatGPT, mais il manque encore un petit quelque chose…
L’accessibilité.
Ouvrir un navigateur, c’est bien. Mais pouvoir interpeller son propre modèle d’IA directement depuis son outil de travail quotidien, là où se passent les discussions, c’est un tout autre niveau. Aujourd’hui, on va voir comment transformer cette infrastructure locale en un assistant Slack ultra-réactif, totalement privé et surtout, sécurisé.
Le défi de la sécurité : Pourquoi le « Socket Mode » ?
Quand on parle de connecter un serveur local à un service cloud comme Slack, le premier réflexe est souvent de se dire : « Je vais devoir ouvrir un port sur ma box, gérer un DNS dynamique, un certificat SSL… ».
Oubliez tout ça. Ouvrir des ports, c’est créer des trous dans votre muraille de Chine personnelle. Pour cet article, on va utiliser le Socket Mode. C’est une technologie qui permet à notre petit bot Python, bien au chaud derrière votre pare-feu local, d’ouvrir lui-même une connexion vers Slack pour récupérer les messages. C’est le bot qui « écoute » Slack via une connexion sortante, et non Slack qui « appelle » votre serveur.
Résultat : Sécurité maximale. Votre IP reste cachée, aucun port n’est ouvert, et votre IA reste souveraine.
Étape 1 : Préparer le terrain sur Slack
Avant de toucher au code, il faut donner une existence légale à notre assistant sur l’interface développeur de Slack.
- Rendez-vous sur le portail API de Slack et créez une application « From Scratch ».
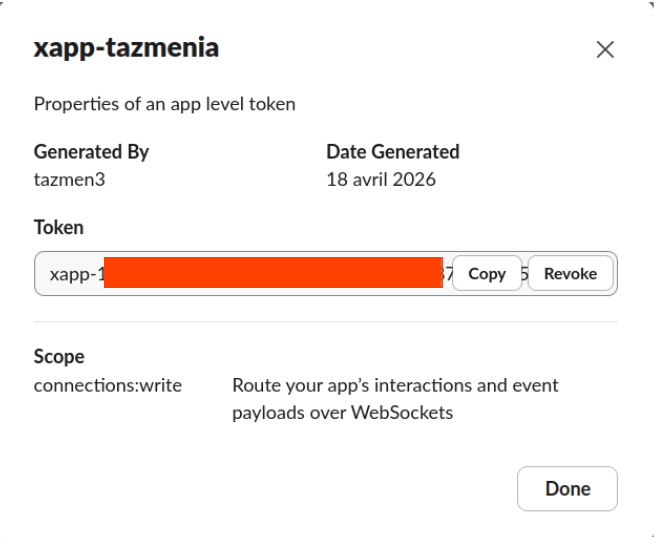
- Activer le Socket Mode : C’est l’option la plus importante dans le menu de gauche. En l’activant, Slack vous donnera un premier token (commençant par
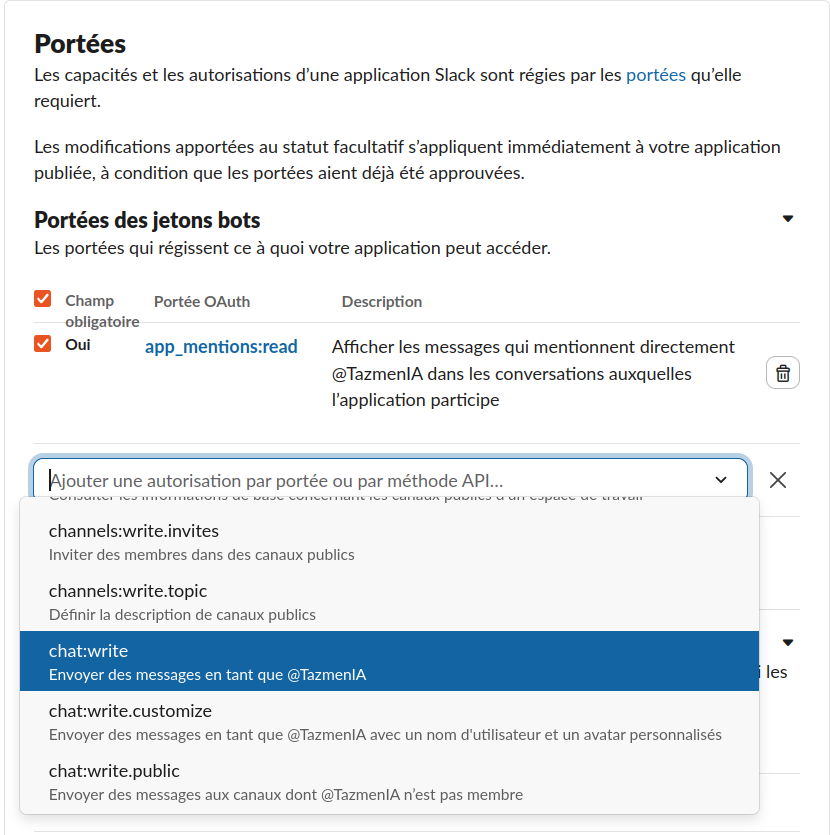
xapp-). C’est la clé de votre tunnel sécurisé. - Permissions (Scopes) : Votre bot a besoin de voir les mentions (
app_mentions:read) et de pouvoir répondre (chat:write). Si vous voulez lui parler en privé, ajoutez aussi les permissions liées aux messages directs (im:history).
Étape 2 : L’architecture Docker (La modularité avant tout)
Dans l’article précédent, on a vu que Docker était notre meilleur allié pour isoler nos services. Pour ajouter le bot Slack, on ne va pas polluer notre conteneur Ollama. On va créer un nouveau service dédié.
Voici à quoi ressemble notre infrastructure mise à jour. J’ai anonymisé les chemins et les clés, mais la structure est celle que j’utilise au quotidien.
1. Le fichier docker-compose.yml
C’est le chef d’orchestre. Il définit comment Ollama et ton Bot communiquent dans un réseau privé.
# docker-compose.yml (Extrait)
services:
# Votre moteur IA que nous avons configuré auparavant
ollama:
image: ollama/ollama
container_name: ollama
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
# Le nouveau venu : Notre pont Python personnalisé
slack-bot:
build: ./slack-bot
container_name: slack-bot
depends_on:
- ollama
environment:
- SLACK_BOT_TOKEN=xoxb-votre-cle-secrete # Token de l'App
- SLACK_APP_TOKEN=xapp-votre-cle-tunnel # Token Socket Mode
- PYTHONUNBUFFERED=1 # Pour voir les logs en temps réel
restart: unless-stopped2. Le fichier slack-bot/requirements.txt
slack_bolt
requests3. Le fichier slack-bot/Dockerfile
Les instructions pour construire l’image de ton bot.
FROM python:3.11-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY bot.py .
CMD ["python", "bot.py"]4. Le fichier slack-bot/bot.py (Version avec Mémoire)
C’est ici que la magie opère. Ce script gère les messages directs, les mentions, et conserve l’historique pour que l’IA ait du contexte.
Les dépendances Python nécessaires pour faire tourner le bot.
import os
import requests
from slack_bolt import App
from slack_bolt.adapter.socket_mode import SocketModeHandler
# Configuration
app = App(token=os.environ.get("SLACK_BOT_TOKEN"))
OLLAMA_URL = "http://ollama:11434/api/chat"
MODEL_NAME = "ministral-3:14b-instruct-2512-q4_K_M"
# Mémoire locale (Dictionnaire par utilisateur)
history_db = {}
def get_ai_response(user_id, user_text):
# Initialiser l'historique si nouveau
if user_id not in history_db:
history_db[user_id] = []
# Ajouter le message utilisateur
history_db[user_id].append({"role": "user", "content": user_text})
# Garder les 10 derniers messages pour le contexte
history_db[user_id] = history_db[user_id][-10:]
payload = {
"model": MODEL_NAME,
"messages": history_db[user_id],
"stream": False
}
try:
r = requests.post(OLLAMA_URL, json=payload)
r.raise_for_status()
bot_response = r.json()['message']['content']
# Mémoriser la réponse de l'IA
history_db[user_id].append({"role": "assistant", "content": bot_response})
return bot_response
except Exception as e:
return f"Désolé, j'ai eu un souci technique : {e}"
# Écouteur pour les messages directs (DM)
@app.event("message")
def handle_message(event, say):
if event.get("channel_type") == "im" and "bot_id" not in event:
response = get_ai_response(event['user'], event['text'])
say(response)
# Écouteur pour les mentions (@MonBot)
@app.event("app_mention")
def handle_mention(event, say):
# On nettoie la mention pour ne garder que la question
text = event['text'].split('> ')[-1] if '>' in event['text'] else event['text']
response = get_ai_response(event['user'], text)
say(response)
if __name__ == "__main__":
handler = SocketModeHandler(app, os.environ.get("SLACK_APP_TOKEN"))
handler.start()L’avantage de cette méthode ? Si vous voulez changer de modèle d’IA ou mettre à jour Ollama, votre bot Slack n’a pas besoin d’être modifié. Il attend simplement que le moteur soit prêt.
Étape 3 : Donner un cerveau (et une mémoire) au Bot
C’est là que le côté « humain » intervient. Un bot qui répond à une question, c’est bien. Un bot qui se souvient que vous lui avez parlé d’un projet de blog il y a trois messages, c’est mieux.
Par défaut, les API de LLM sont « amnésiques ». Chaque question repart de zéro. Pour corriger ça, on utilise un script Python qui va stocker les derniers échanges dans une petite structure de données (un dictionnaire) avant d’envoyer le tout à l’API /api/chat d’Ollama.
Le script va filtrer les mentions, nettoyer le texte et s’assurer que si vous l’appelez dans un canal public ou en message privé, il sache qui vous êtes.
Note sur l’anonymisation : Dans le code, on ne manipule jamais de noms réels, seulement des user_id fournis par Slack. C’est une couche de confidentialité supplémentaire.
Étape 4 : Le premier démarrage (Et les logs magiques)
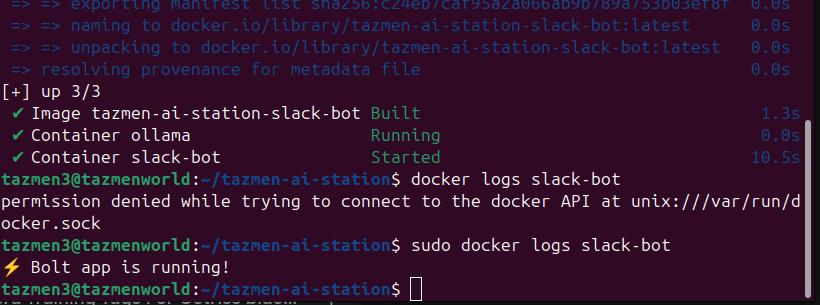
Une fois le code prêt, on lance la machine : docker compose up -d --build
C’est le moment de vérité. On regarde les logs du conteneur. Si vous voyez s’afficher ⚡️ Bolt app is running!, félicitations : votre GPU est désormais branché sur Slack.
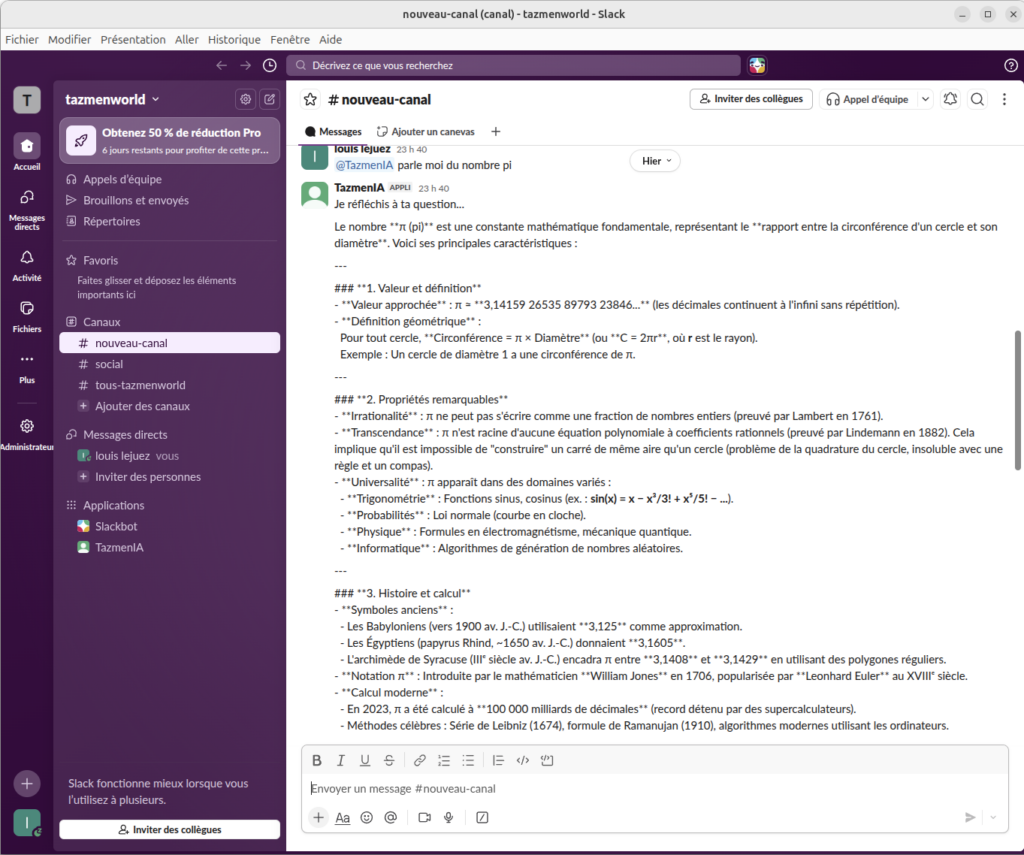
Étape 5 : L’IA en action (Tests et ressentis)
En testant avec Mistral Nemo (en version instruct, quantifié en Q8 pour garder de la précision), les réponses sont bluffantes.
Ce qui change tout par rapport à une interface web, c’est la fluidité. On pose une question technique sur un bout de code, on continue sa discussion avec ses collègues, et on voit la petite notification Slack arriver quand l’IA a fini de « réfléchir ». C’est moins intrusif et beaucoup plus intégré au flux de travail.
Conclusion : Souveraineté et Futur
En trois étapes, nous sommes passés d’une machine Linux brute à un assistant personnel capable de rivaliser avec les meilleurs services payants, le coût du cloud et l’espionnage en moins.
Ce projet montre qu’en 2026, l’IA locale n’est plus une curiosité pour les geeks du dimanche. C’est un outil de production sérieux, sécurisé, et totalement personnalisable. La prochaine étape ? Pourquoi ne pas donner à ce bot la capacité de lire vos documents locaux ou d’automatiser vos déploiements Docker ?
Mais ça, c’est peut-être le sujet d’un futur article…
D’ici là, reprenez le contrôle de vos données, et amusez-vous bien avec votre nouveau collègue de bureau virtuel !