Si tu suis mes articles sur l’optimisation hardware et le scripting headless, tu sais que je ne suis pas du genre à m’emballer pour les communiqués de presse lisses ou les promesses marketing. Mais aujourd’hui, on va lever le nez du terminal pour regarder un dossier qui va sérieusement bousculer nos habitudes.
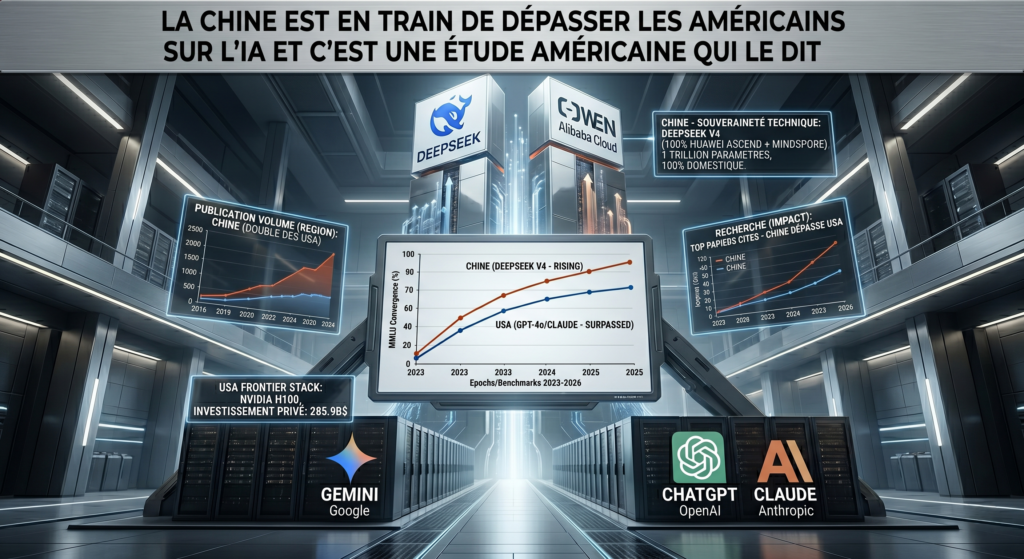
Le baromètre mondial de l’IA (le fameux AI Index Report 2026 de Stanford) vient de sortir, et c’est une sacrée douche froide pour ceux qui pensaient que l’hégémonie de la Silicon Valley était gravée dans le marbre. On ne parle pas de spéculation ou de propagande, mais de faits documentés par l’élite universitaire américaine : la Chine n’est plus dans le rétroviseur, elle est en train de déboîter sur la file de gauche.
Dans cet article, on va plonger dans le dur. On va voir comment les ingénieurs chinois ont réussi à transformer les sanctions sur les puces en un moteur pour leur propre souveraineté technique. On va parler de modèles massifs entraînés sans une seule puce Nvidia, de la fin de la dépendance à TSMC et de ce que cela signifie concrètement pour nos futures infras. Pas de langue de bois, juste de la technique, des chiffres et de la géopolitique appliquée. Attache ta ceinture, on va parler puissance brute et silicium.
L’évaporation de l’écart technique : les chiffres qui fâchent
Pendant que les médias occidentaux se focalisaient sur les chatbots capables de générer des poèmes, les labos chinois ont bossé sur la performance brute. Le rapport de Stanford met en lumière une donnée qui devrait donner des sueurs froides à la tech américaine : l’écart de performance entre les meilleurs modèles américains et les fleurons chinois comme DeepSeek ou Qwen est désormais inférieur à 3 %.
En mars 2026, sur les benchmarks les plus exigeants ceux qui testent le codage informatique complexe, les mathématiques de niveau compétition et les raisonnements scientifiques de niveau doctorat la supériorité américaine est devenue un concept purement théorique. Pour nous, qui utilisons ces outils pour automatiser des workflows ou scripter des tâches complexes, la différence est devenue imperceptible en production.
Le cas DeepSeek V4 : 1000 milliards de paramètres sans Nvidia
C’est ici qu’on entre dans le vif du sujet hardware. Les USA ont misé gros sur l’embargo des puces H100 et H200 de Nvidia pour freiner la Chine. Ils ont pensé qu’en coupant l’accès au silicium de pointe produit par TSMC, ils bloqueraient net la capacité de calcul chinoise.
C’est exactement l’inverse qui s’est produit. Le rapport mentionne l’émergence de DeepSeek V4, un modèle massif de 1 000 milliards de paramètres. La véritable claque technique réside dans le fait que ce modèle a été entraîné à 100 % sur des clusters de puces Huawei Ascend.
Habituellement, l’entraînement de modèles de cette taille nécessite une interconnexion ultra-rapide entre les puces, un domaine où Nvidia régnait sans partage avec son protocole NVLink. Huawei a réussi à développer sa propre stack complète pour contourner ce goulot d’étranglement :
- Les puces Ascend qui, bien que moins performantes par unité que les dernières Blackwell de Nvidia, sont optimisées pour travailler en clusters géants de manière très cohérente.
- Un framework propriétaire, MindSpore, qui remplace PyTorch et qui est taillé sur mesure pour exploiter le silicium domestique.
- Une indépendance totale vis-à-vis de TSMC pour la production, la Chine ayant réussi à optimiser ses procédés de lithographie pour sortir des volumes suffisants de puces de calcul performantes.
On est passé d’une dépendance critique à une autonomie forcée. La Chine a appris à faire de l’IA avec son propre hardware, là où le reste du monde est encore suspendu aux carnets de commandes de Nvidia.
L’architecture MoE et l’optimisation au couteau
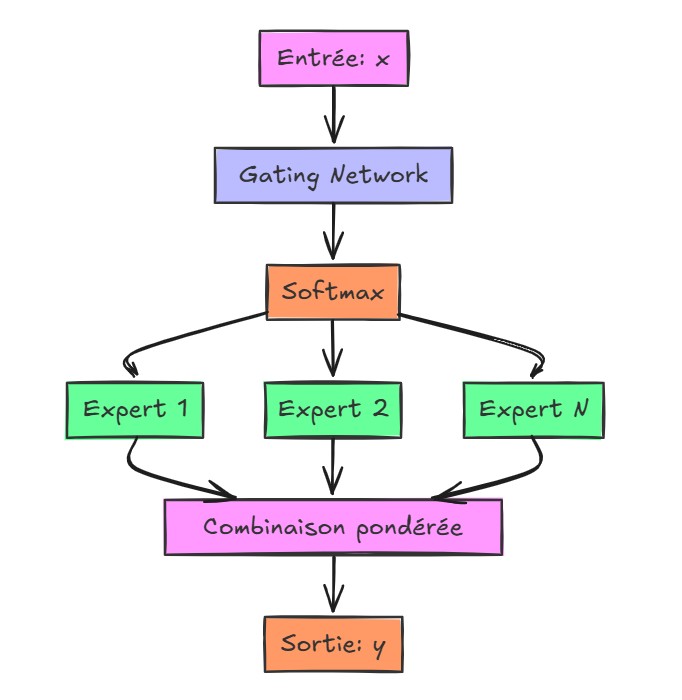
Si tu as lu mes posts sur le VRAM tuning, tu sais que la mémoire est le nerf de la guerre. Les ingénieurs chinois n’ont pas cherché à copier bêtement l’approche de puissance brute adoptée par OpenAI. Ils ont poussé l’architecture Mixture of Experts (MoE) dans ses derniers retranchements.
L’idée est simple : au lieu d’activer les 1000 milliards de paramètres à chaque requête, le modèle ne sollicite que les experts concernés par le sujet. Cela permet de réduire la consommation électrique et, surtout, de faire tourner des modèles très puissants sur des configurations hardware qui auraient été jugées insuffisantes il y a deux ans. En clair, ils font plus avec moins de VRAM, ce qui est un avantage stratégique énorme quand on a un accès limité au hardware de pointe.
La fuite des cerveaux à l’envers : l’impact politique
Le rapport de Stanford souligne un point critique sur le capital humain, et c’est peut-être là que le bât blesse le plus pour Washington. Historiquement, les USA étaient un aspirateur à talents sans équivalent. Un étudiant chinois brillant finissait ses études à Stanford et restait bosser dans la Silicon Valley pour créer de la valeur aux États-Unis.
Ce cycle vertueux pour l’économie américaine est en train de se briser. Le rapport note une chute brutale de 89 % des arrivées de chercheurs étrangers en IA aux USA depuis 2017. Cette date n’est pas un hasard : elle marque le début du durcissement drastique de la politique migratoire sous l’administration Trump.
L’image projetée à l’international, marquée par une administration perçue comme hostile aux étrangers et les actions d’une agence comme l’ICE (Immigration and Customs Enforcement) aux méthodes de plus en plus paramilitaires, a créé un climat de méfiance profonde. Pour un chercheur de haut niveau, le rêve américain a été remplacé par l’incertitude des visas et un sentiment d’insécurité.
Aujourd’hui, la majorité des cerveaux formés en Chine, ou même ceux formés aux États-Unis, choisissent de retourner au pays pour monter des structures ou rejoindre des géants comme Baidu, Tencent ou Huawei. Ce n’est plus seulement une guerre de puces, c’est une guerre de neurones, et les USA sont en train de perdre leur force d’attraction principale. La Chine produit désormais plus de papiers de recherche de haut niveau que n’importe quelle autre nation, et la force de leur système est que ces recherches sont immédiatement injectées dans leur tissu industriel.
La frontière en dents de scie et le pragmatisme industriel
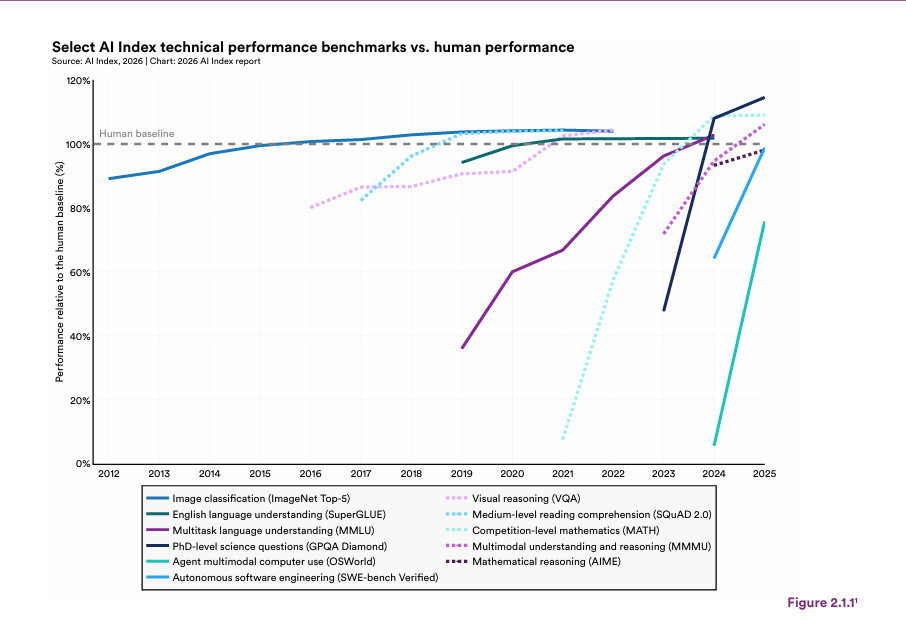
Un concept fondamental du rapport est la Sawtooth Frontier. Cela décrit le fait que l’IA ne progresse pas de manière uniforme. Un modèle peut être un génie en programmation mais être incapable de comprendre un concept social simple.
Alors que les Américains cherchent à créer une Intelligence Artificielle Générale capable de tout faire, les Chinois se concentrent sur une IA de production. Leurs investissements massifs sont fléchés vers des domaines concrets :
- L’optimisation des réseaux électriques et des flux logistiques.
- La conception assistée de nouveaux matériaux et semi-conducteurs.
- L’automatisation de la cybersécurité.
C’est une approche purement utilitaire. Ils ne cherchent pas à ce que l’IA soit humaine, ils cherchent à ce qu’elle soit efficace. C’est du headless appliqué à l’échelle d’un pays : on enlève l’interface polie pour ne garder que le moteur de calcul.
Le coût caché : l’alerte environnementale
Même si la Chine gagne la course, le rapport de Stanford tire une sonnette d’alarme sur le coût énergétique et environnemental. On parle souvent de la consommation des datacenters, mais les chiffres ici sont vertigineux. L’entraînement d’un modèle comme DeepSeek V4 consomme plus d’eau pour le refroidissement que ce que consomme une ville moyenne en un an.
La Chine, avec ses besoins énergétiques monstrueux, semble prête à payer ce prix pour la domination technologique. C’est un facteur que les régulations européennes ou américaines pourraient limiter chez nous, créant un nouveau déséquilibre compétitif majeur.
Conclusion : On fait quoi maintenant ?
On ne va pas se mentir : le centre de gravité a basculé. Ce rapport de Stanford n’est pas une simple étude de plus, c’est l’aveu de la fin d’un monopole. Pour nous, les techniciens, cela signifie que notre boîte à outils va changer.
Il va falloir apprendre à bosser avec ces modèles venus d’ailleurs, comprendre leurs frameworks et arrêter de penser que si ce n’est pas développé en Californie, c’est forcément moins bon. La réalité du terrain, celle des benchmarks et des clusters de serveurs, raconte une tout autre histoire.
On est à l’aube d’une ère où la puissance de calcul ne dépendra plus d’une seule marque de cartes graphiques ou d’une seule fonderie à Taïwan. C’est le retour de la diversité technique, et pour ceux qui aiment l’optimisation et la performance, c’est un nouveau terrain de jeu passionnant.
On se retrouve pour le prochain article où on verra comment installer et quantifier localement ces nouveaux modèles pour voir ce qu’ils ont vraiment dans le ventre.
Analyse comparative (Données Stanford AI Index 2026)
| Critère | Bloc Américain | Bloc Chinois |
| Hardware dominant | Nvidia (Série H/Blackwell) | Huawei (Série Ascend) |
| Dépendance TSMC | Totale (N3/N2) | En forte diminution |
| Stratégie de modèle | AGI / Conversationnel | Industriel / Efficience MoE |
| Flux de talents | En baisse (Immigration -89%) | En hausse (Rétention interne) |
| Contexte politique | Instabilité des visas / ICE | Souveraineté et rapatriement |
Source: https://hai.stanford.edu/ai-index