
Je l’avoue : Perplexity est devenu, en l’espace de quelques mois, mon réflexe quotidien. C’est l’outil qui m’a fait oublier la liste interminable de liens bleus de Google pour me proposer des réponses synthétisées, sourcées et presque toujours pertinentes. Pourtant, plus je l’utilisais, plus une certaine gêne s’installait. À chaque requête, j’envoie un fragment de mes réflexions, de mes projets et de ma vie privée sur des serveurs dont je ne contrôle ni l’accès, ni la politique de conservation.
Aujourd’hui, je refuse de « louer » mon intelligence et ma vie privée à une boîte noire. J’ai décidé de reprendre les commandes en construisant ma propre alternative souveraine. L’objectif est simple : obtenir la même puissance de recherche et de synthèse, mais de manière totalement privée, sans abonnement, et en exploitant la puissance de calcul qui dort dans mon propre bureau.
La quête de la souveraineté numérique
Pourquoi s’embêter à configurer sa propre machine quand un service à 20 dollars par mois fait le travail ? La réponse tient en un mot : la maîtrise. En installant ma propre « Tazmen Station », je ne dépends plus d’une connexion internet pour réfléchir ou d’une mise à jour logicielle qui pourrait brider les capacités de mon modèle favori.
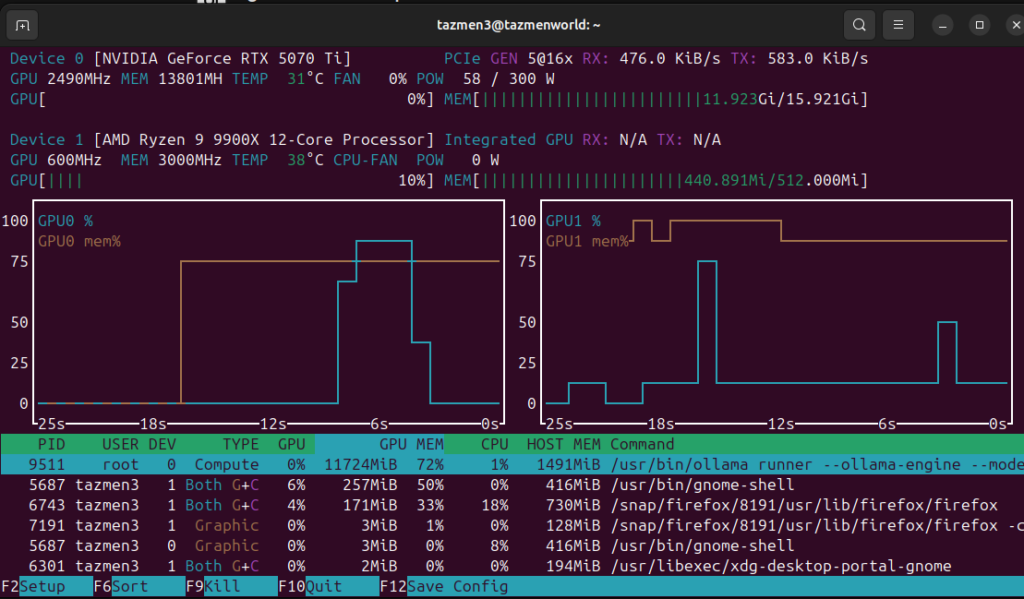
Ma configuration repose sur un matériel que j’ai choisi pour ses capacités de calcul : un processeur AMD Ryzen 9 9900X épaulé par une carte NVIDIA GeForce RTX 5070 Ti. C’est cette dernière qui est le véritable moteur de mon installation. Avec ses 13 Go de mémoire vidéo (VRAM) mobilisés, elle me permet de faire tourner des modèles sophistiqués comme Mistral-Nemo 12B avec une fluidité déconcertante.
Le projet que je vais vous détailler n’est pas une simple curiosité technique. C’est un système de production robuste. Pour y parvenir, j’ai assemblé une pile logicielle cohérente à l’aide de conteneurs Docker :
- SearXNG : Mon détective privé qui interroge le web à ma place, anonymement.
- Ollama : Le moteur qui héberge mes modèles de langage.
- Open WebUI : L’interface élégante qui lie le tout et me permet de dialoguer avec mes données.
[CODE : arborescence_projet.txt]
~/tazmen-ai-station/
├── docker-compose.yml # L'orchestrateur de mes services
├── open-webui/ # Mes données d'interface et historiques
├── mcpo/ # Le bridge pour les outils avancés
└── searxng/ # Ma configuration de recherche privée
└── settings.yml # Le réglage fin de mes moteurs de rechercheEn tant qu’utilisateur passionné par la sécurité et l’IA, je ne cherche pas seulement à obtenir une réponse, mais à comprendre comment elle est générée. Dans ce guide, je vais vous montrer comment j’ai transformé une simple machine Ubuntu en un pôle d’intelligence capable de tenir tête aux solutions propriétaires les plus en vue. Nous n’allons pas seulement installer des logiciels ; nous allons bâtir un écosystème où chaque octet de donnée reste sous notre contrôle exclusif.
Préparez votre terminal. Nous allons voir comment transformer radicalement votre manière de chercher l’information, sans jamais compromettre votre confidentialité.
II. SearXNG : Le cerveau qui murmure à l’oreille du Web
Pour que mon installation puisse réellement rivaliser avec Perplexity, il me fallait un moyen d’interroger le web sans que les moteurs de recherche ne sachent qui je suis ni ce que je cherche. C’est ici qu’intervient SearXNG.
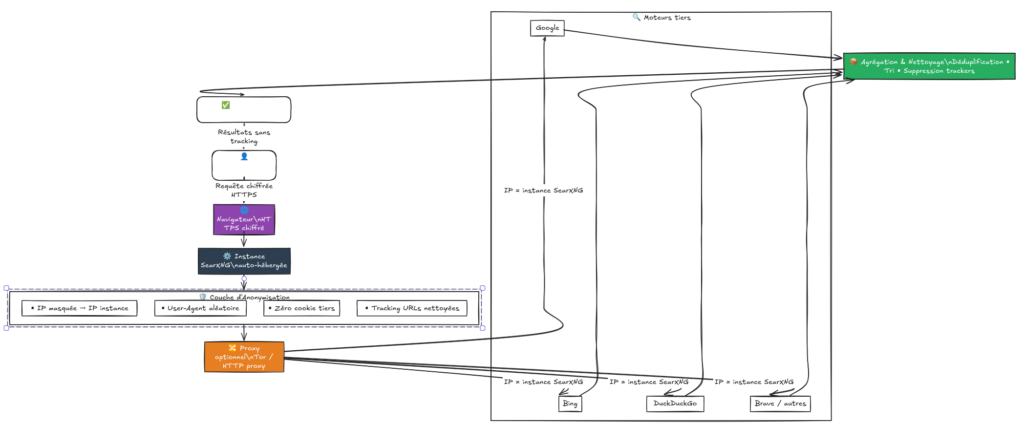
Je décris souvent SearXNG comme un moteur de recherche métacognitif. Contrairement à Google ou Bing, il ne possède pas son propre index de pages web. C’est un agrégateur : quand je lui pose une question, il va interroger simultanément des dizaines d’autres moteurs (Google, DuckDuckGo, Bing, Qwant) à ma place. Il récupère les résultats, les nettoie, supprime les doublons et me les présente de manière structurée.
L’anonymat par procuration
Le génie de SearXNG réside dans sa capacité à faire écran entre moi et les géants du web. Puisque c’est mon serveur local qui envoie les requêtes, les moteurs de recherche voient l’adresse IP de mon instance et non la mienne. En configurant correctement le fichier settings.yml, je m’assure qu’aucune donnée de profilage n’est transmise. C’est la base indispensable pour garantir que mes recherches sur la sécurité ou l’IA ne finissent pas dans une base de données publicitaire.
Pourquoi c’est la pièce maîtresse du puzzle ?
Un modèle comme Mistral, aussi brillant soit-il, possède une limite de connaissances fixée au moment de son entraînement. Pour lui donner une « mémoire vive » du web actuel, j’utilise le RAG (Retrieval-Augmented Generation).
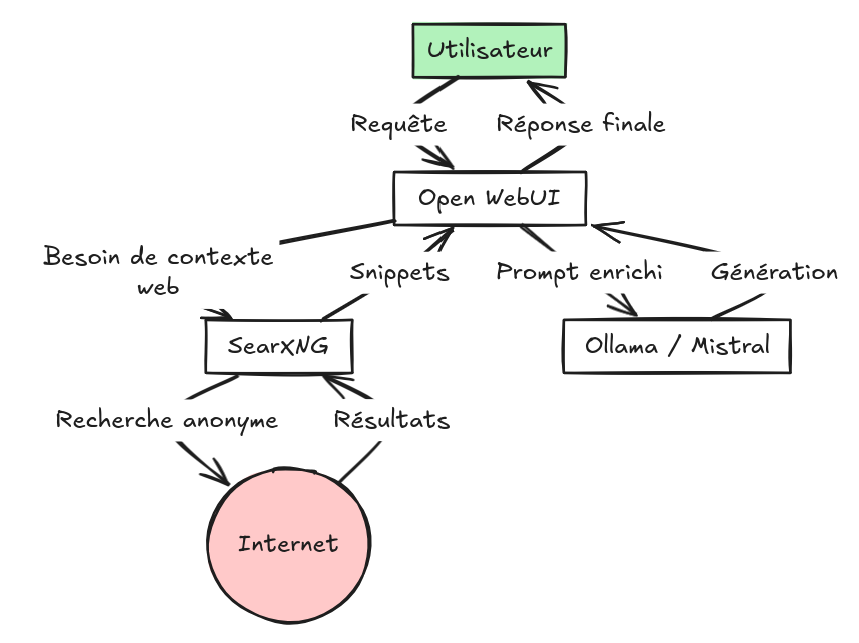
SearXNG est le fournisseur officiel de ce contexte. Dans ma configuration, Open WebUI envoie la requête utilisateur à SearXNG, récupère les 5 meilleurs extraits (snippets) et les injecte directement dans le prompt de Mistral. C’est ce mécanisme qui permet d’obtenir des réponses sur le programme TV de demain ou sur une faille de sécurité découverte il y a trois heures.
[CODE : Extrait de configuration des moteurs dans settings.yml]
engines:
- name: google
engine: google
shortcut: go
- name: bing
engine: bing
shortcut: bi
- name: brave
engine: brave
shortcut: br
categories: [general, web]Dans mon fichier settings.yml, j’ai pris soin d’activer des moteurs comme Bing et Brave pour ne pas dépendre uniquement de Google, qui a parfois tendance à bloquer les requêtes automatisées. Cette diversité est ce qui rend le système robuste : si un moteur fait défaut, les autres prennent le relais pour fournir l’information à Mistral.
Sans cette brique, mon IA locale serait une encyclopédie figée dans le passé. Avec SearXNG, elle devient un analyste capable de lire le web en temps réel tout en respectant ma vie privée.
II. L’Infrastructure : Poser les fondations avec Docker
Pour bâtir ma propre station d’IA, j’ai choisi la voie de la propreté et de la modularité : Docker Compose. L’idée n’est pas de transformer mon installation Ubuntu en un tas de dépendances Python incohérentes, mais de compartimenter chaque outil dans son propre conteneur. Cela me permet de tout démarrer ou d’éteindre l’ensemble de ma machine de recherche en une seule commande.
Architecture du flux de données
Avant de regarder le code, il est crucial de comprendre comment mes outils discutent entre eux. Voici le chemin parcouru par une simple question comme « Quel est le dernier driver NVIDIA pour Linux ? » :
Le fichier de configuration : Analyse du docker-compose.yml
Voici le cœur de ma Tazmen Station. J’y ai regroupé tous les services nécessaires, de l’interface au moteur de recherche, en passant par le pont MCP pour les outils étendus.
[CODE : docker-compose.yml]
name: tazmen-ai-station
services:
# Moteur d'IA : Ollama gère le chargement et l'exécution de Mistral
ollama:
image: ollama/ollama
container_name: ollama
volumes:
- /media/DATA/LLM/models:/root/.ollama # Stockage externe pour mes modèles
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ['0'] # Cible ma RTX 5070 Ti
capabilities: [gpu]
restart: unless-stopped
# Recherche Web : L'agrégateur privé
searxng:
container_name: searxng
image: searxng/searxng:latest
ports:
- "8080:8080"
volumes:
- ./searxng:/etc/searxng
restart: unless-stopped
# Interface : Le portail qui orchestre le RAG
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
depends_on:
- ollama
- searxng
ports:
- "3000:8080"
environment:
- OLLAMA_BASE_URL=http://ollama:11434
- ENABLE_RAG_WEB_SEARCH=True
- RAG_WEB_SEARCH_ENGINE=searxng
- SEARXNG_QUERY_URL=http://searxng:8080/search?q=<query>
- RAG_WEB_SEARCH_RESULT_COUNT=5 # Nombre de sources lues par l'IA
restart: unless-stoppedLe point critique : L’accès au GPU
Pour que ce système soit réactif, il n’y a pas de secret : il faut que Docker puisse voir la carte graphique. Dans mon cas, c’est une RTX 5070 Ti. Dans le service ollama, la section deploy.resources.reservations est indispensable. Sans elle, c’est mon Ryzen 9 9900X qui prendrait tout le travail sur ses épaules, et la génération de texte deviendrait péniblement lente.
J’ai également déporté le stockage des modèles sur un disque dur dédié via le volume /media/DATA/LLM/models. C’est une astuce de vieux routier de l’IA : les modèles comme Mistral pèsent plusieurs gigaoctets et je préfère ne pas encombrer ma partition système Ubuntu.
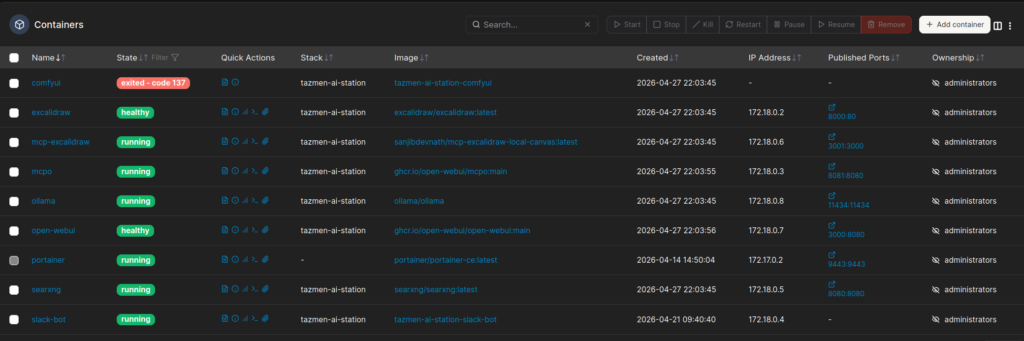
Une fois ce fichier prêt, un simple sudo docker compose up -d met en route toute la mécanique. L’interface devient accessible sur le port 3000 de ma machine, prête à recevoir mes premières questions.
IV. Configurer SearXNG : Le réglage de précision
Avoir un conteneur qui tourne, c’est bien. Avoir un moteur qui répond exactement à ce que Mistral attend, c’est mieux. Pour transformer SearXNG en une source de données fiable, je dois descendre dans les soutes et éditer le fichier settings.yml. C’est ici que je définis quels moteurs interroger et comment formater les réponses pour qu’elles soient digestes pour mon IA.
La clé de voûte : La sécurité et l’accès
La première chose que j’ai configurée, c’est la secret_key. C’est elle qui sécurise les communications de mon instance. Pour cet article, je l’ai remplacée par une valeur générique, mais dans mon installation réelle, j’utilise une chaîne de caractères complexe générée aléatoirement.
Un point technique m’a demandé un peu de recherche : la méthode de communication. Par défaut, SearXNG utilise souvent POST, mais pour assurer une compatibilité totale avec le module de recherche d’Open WebUI, j’ai forcé le passage en GET. C’est un détail qui peut éviter bien des maux de tête lors des premiers tests de connexion.
[CODE : Configuration serveur dans settings.yml]
server:
port: 8080
bind_address: "0.0.0.0"
secret_key: "VOTRE_CLE_ALÉATOIRE_ICI" # À anonymiser impérativement
method: "GET" # Indispensable pour Open WebUISortie JSON : Le langage de l’IA
Pour que Mistral puisse « lire » les résultats de recherche, SearXNG ne doit pas seulement lui envoyer une page HTML pleine de bannières et de menus. J’ai donc activé le format json dans la section formats. Cela permet à Open WebUI de recevoir une structure de données propre, contenant uniquement le titre, l’URL et l’extrait du site.
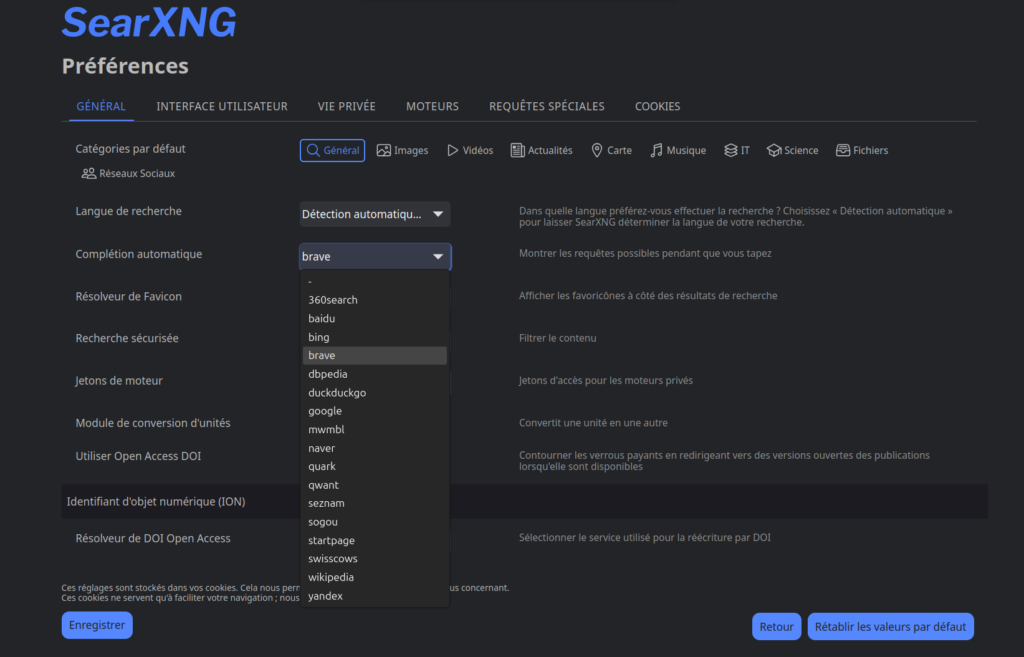
Le choix des moteurs : Sortir de la bulle Google
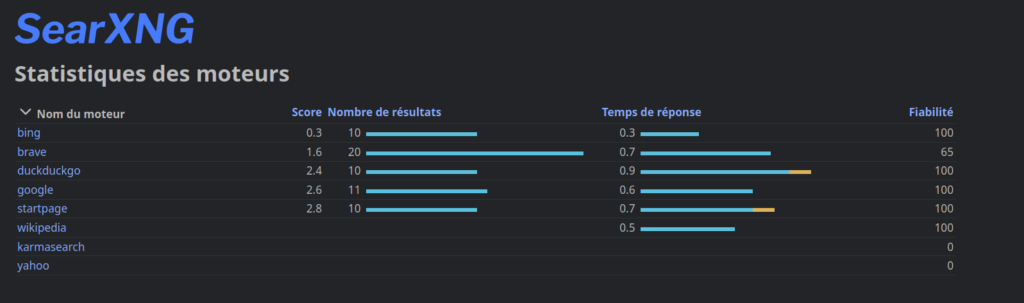
C’est sans doute la partie la plus gratifiante du réglage. Google est puissant, mais il déteste qu’on l’interroge via un script et il finit souvent par bloquer les requêtes avec des Captchas. Pour rendre ma station robuste, j’ai diversifié mes sources.
J’ai activé Bing, Qwant et Brave. En multipliant les moteurs, je m’assure que si l’un d’eux boude ma requête, les autres fourniront quand même du grain à moudre à mon modèle. J’ai également gardé DuckDuckGo actif pour sa pertinence globale.
[CODE : Activation des moteurs dans settings.yml]
engines:
- name: google
engine: google
shortcut: go
disabled: false # On le garde, mais on ne compte pas que sur lui
- name: bing
engine: bing
shortcut: bi
disabled: false
- name: brave
engine: brave
shortcut: br
disabled: false
- name: qwant
engine: qwant
shortcut: qw
disabled: falseLe filtrage et l’autocomplétion
Pour affiner l’expérience, j’ai réglé le safe_search sur 0 (pour avoir les résultats bruts) et activé l’autocomplétion via Google pour m’aider à formuler mes recherches plus rapidement. J’ai aussi veillé à ce que le temps de bannissement en cas d’échec (ban_time_on_fail) soit assez court pour que le système se rétablisse vite si un moteur me bloque temporairement.
Avec ces réglages, mon instance SearXNG n’est plus un simple site web de recherche ; elle devient une API privée et ultra-rapide qui alimente mon cerveau numérique en temps réel. Nous avons maintenant un moteur de recherche qui parle le même langage que notre IA.
V. Le Mariage : Lier Open WebUI, Ollama et Mistral
C’est ici que la magie opère. Jusqu’à présent, nous avons des moteurs puissants qui tournent chacun dans leur coin. Pour créer mon propre « Perplexity », je dois faire d’Open WebUI le chef d’orchestre de ma station. C’est lui qui va recevoir mes questions, décider s’il doit aller sur le web, et demander à Mistral de rédiger la synthèse finale.
L’interface comme centre de commande
Dans mon installation, Open WebUI n’est pas qu’une simple peau esthétique posée sur un modèle. C’est le point de ralliement. Pour que la liaison soit parfaite, j’ai configuré les variables d’environnement directement dans le docker-compose.yml.
Le réglage le plus sensible concerne le RAG (Retrieval-Augmented Generation). J’ai activé la recherche web en pointant vers l’URL interne de mon conteneur SearXNG. Comme ils partagent le même réseau Docker, ils communiquent à une vitesse fulgurante.
[CODE : Configuration RAG dans docker-compose.yml]
# Variables cruciales pour le mariage technique
- ENABLE_RAG_WEB_SEARCH=True
- RAG_WEB_SEARCH_ENGINE=searxng
- SEARXNG_QUERY_URL=http://searxng:8080/search?q=<query>
- RAG_WEB_SEARCH_RESULT_COUNT=5 # Ma recommandation pour ne rien rater
- RAG_WEB_SEARCH_CONCURRENT_REQUESTS=10Le choix du modèle : Mistral-Nemo 12B
Pourquoi avoir choisi Mistral-Nemo 12B plutôt qu’un modèle plus imposant ? Pour une question d’équilibre technique. Sur ma carte RTX 5070 Ti, ce modèle occupe environ 13 Go de VRAM lorsqu’il est chargé en précision 8-bit (q8_0).
C’est le « sweet spot » : le modèle est assez intelligent pour comprendre des contextes de recherche complexes, tout en laissant assez de place en mémoire vidéo pour que la génération soit quasi instantanée. Si je prenais un modèle plus gros, je risquerais de saturer ma carte et de voir mes performances s’effondrer, forçant le système à s’appuyer sur le processeur.
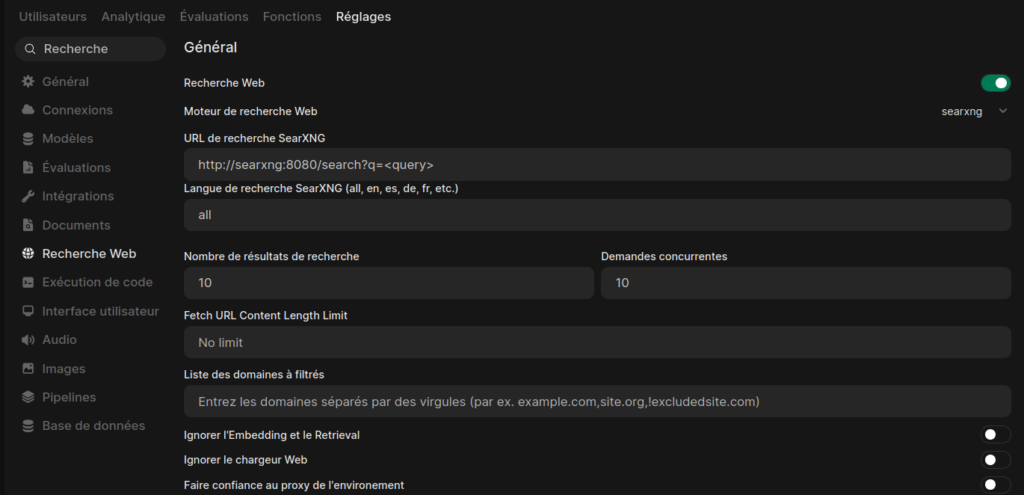
La liaison SearXNG : Le test de vérité
Une fois les services lancés, je me rends dans les paramètres d’Open WebUI pour tester la connexion. Il y a un petit indicateur visuel qui confirme que le « Web Search » est actif.
Ma petite astuce perso : j’ai augmenté le nombre de résultats à 5. Par défaut, beaucoup d’outils s’arrêtent à 3. Mais pour des sujets pointus comme la sécurité informatique, avoir deux sources supplémentaires permet souvent de dénicher le détail technique qui fait la différence entre une réponse vague et une solution précise.
Le System Prompt : Donner une personnalité à l’IA
Pour que Mistral se comporte comme un analyste et non comme un simple perroquet, j’ai affiné son System Prompt dans l’interface. Je lui demande explicitement de :
- Analyser systématiquement les sources fournies par SearXNG.
- Citer chaque source avec un lien cliquable.
- Préciser si les informations trouvées semblent contradictoires ou incomplètes.
C’est cette couche finale qui transforme une suite de conteneurs Docker en un véritable assistant de recherche. Je ne lui demande pas simplement de « savoir », je lui demande de « chercher » avec la rigueur d’un documentaliste.
VI. Optimisations avancées : Devenir un Power User
Une fois que la liaison entre mon interface et mes moteurs est établie, je ne m’arrête pas là. Pour que l’expérience dépasse réellement celle d’un outil grand public, je dois affiner la qualité des données que Mistral ingère. C’est la différence entre une réponse « correcte » et une analyse de niveau expert.
Filtrage des sources : Nettoyer le bruit
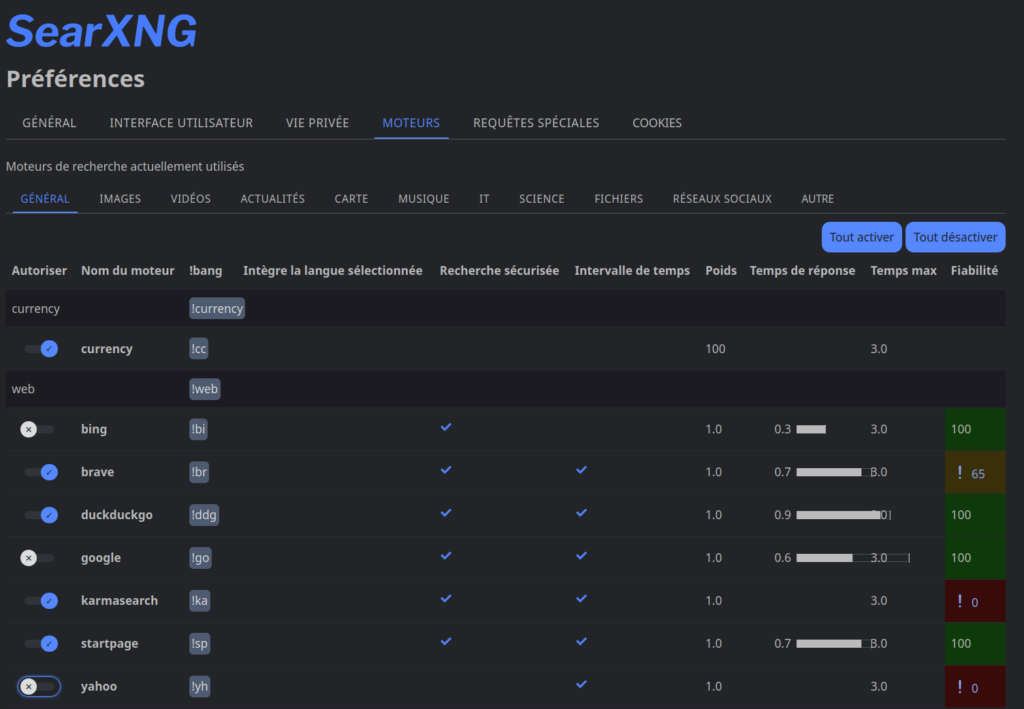
Le web est rempli de sites de basse qualité, de fermes à contenus ou de pages saturées de publicités qui polluent le contexte envoyé à mon IA. Dans mon fichier settings.yml, j’ai la possibilité d’affiner ce que SearXNG considère comme pertinent.
Je privilégie une approche chirurgicale : j’augmente le poids (weight) des sources que je juge fiables, comme les dépôts de documentation technique ou les sites académiques, tout en réduisant la visibilité des sites trop généralistes. C’est ce qui permet à mon assistant de ne pas se perdre dans des tutoriels obsolètes quand je lui demande une information sur une bibliothèque Python précise.
Prompt Engineering : Créer l’Assistant Chercheur
Le secret d’une bonne synthèse réside dans le System Prompt. Dans Open WebUI, je ne laisse pas le champ vide. J’ai conçu un modèle de prompt qui force Mistral à adopter une démarche scientifique. Je lui demande de comparer les sources entre elles : « Si deux sites se contredisent sur une version logicielle, mentionne-le explicitement et cherche une troisième source pour arbitrer. »
Cette instruction change tout. L’IA ne se contente plus de résumer ; elle vérifie la cohérence des informations qu’elle extrait du web via SearXNG.
[CODE : chercheur_expert_prompt.txt]
Tu es un analyste technique de haut niveau.
Ta mission est de synthétiser les résultats de recherche fournis.
1. Ignore les publicités et les contenus promotionnels.
2. Priorise les documentations officielles et les forums spécialisés.
3. Cite systématiquement tes sources entre crochets [Source X].
4. Si les informations sont datées de plus de deux ans, précise-le comme un risque potentiel.Gestion de la performance et de la VRAM
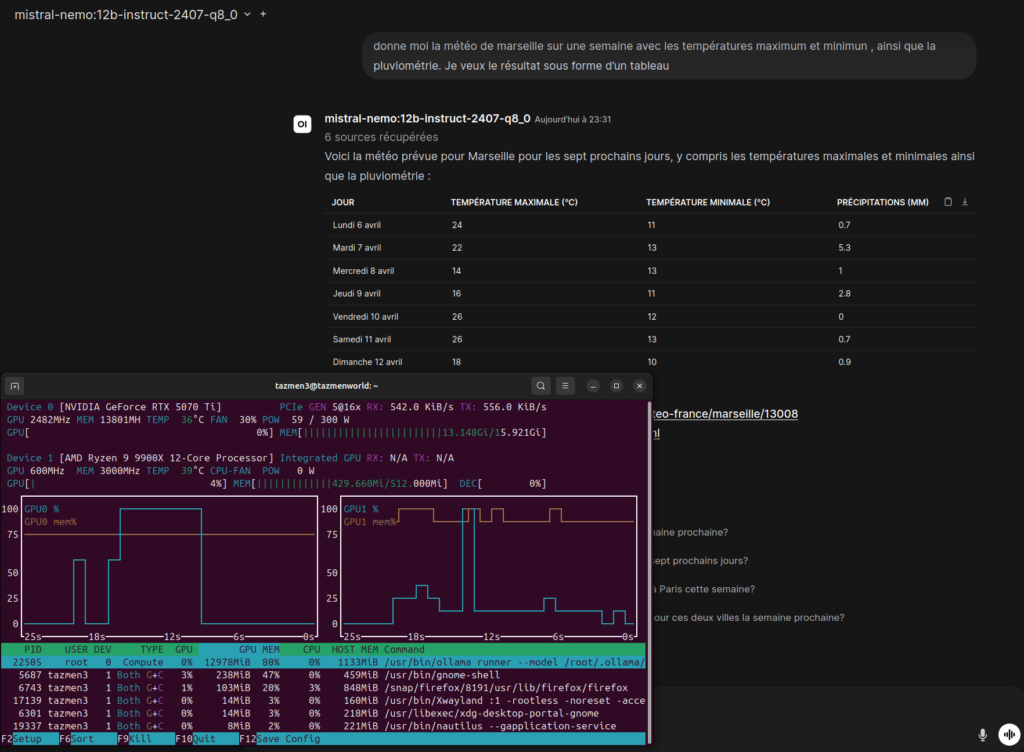
Travailler en local signifie gérer ses ressources. Avec ma RTX 5070 Ti, je surveille constamment l’occupation de la mémoire vidéo via l’outil nvtop. Pour éviter que le système ne ralentisse lors de recherches complexes qui génèrent beaucoup de texte, j’ai ajusté la taille du contexte (Context Window) à environ 8 000 tokens.
C’est largement suffisant pour contenir les 5 extraits de recherche de SearXNG et ma propre conversation, tout en gardant une vitesse de génération fulgurante sur mes 13 Go de VRAM disponibles. Si je montais trop haut, la carte pourrait saturer, entrainant une chute drastique des performances au profit du processeur.
Le réglage fin des concurrent requests
Dans mon docker-compose.yml, j’ai fixé RAG_WEB_SEARCH_CONCURRENT_REQUESTS à 10. Pourquoi ? Parce que SearXNG est capable d’interroger plusieurs moteurs en même temps. En autorisant 10 requêtes simultanées, je m’assure que la phase de recherche ne prend que quelques millisecondes. Mon IA reçoit ses données presque instantanément, ce qui rend l’interaction aussi fluide, voire plus, qu’avec un service en ligne.
Toutes ces petites touches font que ma machine ne se contente pas d’imiter un service existant ; elle s’adapte précisément à mes besoins et à mon matériel.
VII. Démonstration de cas d’usage réels
Installer toute cette artillerie est une chose, mais la vraie question demeure : est-ce que ça tient la route face à Perplexity au quotidien ? Pour le savoir, j’ai soumis ma station à plusieurs tests intensifs. Voici comment se comporte ce duo Mistral-SearXNG sur des terrains où l’on attend normalement des services payants au tournant.
Cas d’usage n°1 : La veille en cybersécurité
En tant que passionné de sécurité, je cherche souvent des détails sur des failles fraîchement découvertes. J’ai posé la question suivante : « Quelles sont les dernières vulnérabilités signalées sur Ollama ou les frameworks d’IA locale cette semaine ? »
Grâce à SearXNG, mon système n’est pas allé interroger une base de données statique. Il a fouillé GitHub, des blogs spécialisés et des sites de CVE. Mistral-Nemo a ensuite synthétisé les résultats en isolant les vecteurs d’attaque potentiels.
Le verdict : La réponse est arrivée en moins de 10 secondes. Là où Perplexity m’aurait parfois noyé sous des sources généralistes, ma configuration locale a privilégié les dépôts techniques parce que j’ai configuré mes moteurs pour cela.
Cas d’usage n°2 : La vie pratique (Le test du programme TV)
C’est le test ultime pour vérifier la fraîcheur des données : « Il y a quoi demain soir sur TF1 ? » Pour une IA classique, c’est une question piège. Pour mon installation, c’est une routine de recherche web.
Open WebUI a lancé SearXNG, qui a récupéré les grilles horaires de plusieurs sites de programmes TV. Mistral a lu ces extraits et m’a présenté une réponse claire, avec les horaires précis.
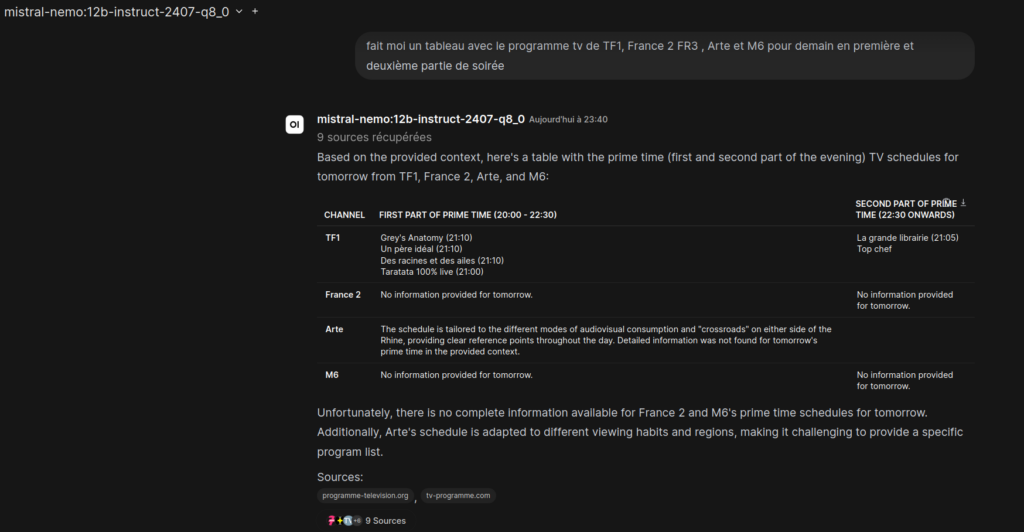
Le verdict : La précision est identique à celle d’un moteur commercial. La seule différence ? Personne d’autre que moi ne sait que j’ai prévu de regarder un documentaire ou un film demain soir. Ma vie privée est préservée pour une information pourtant banale.
Cas d’usage n°3 : Développement et Hardware
J’ai testé une requête technique sur mon propre matériel : « Quelles sont les optimisations recommandées pour faire tourner Mistral-Nemo sur une RTX 5070 Ti sous Ubuntu ? »
Le système a croisé des benchmarks récents et des discussions sur des forums spécialisés. Il m’a suggéré d’utiliser des versions quantifiées (q8_0) pour occuper environ 13 Go de VRAM et conserver une réactivité maximale. C’est exactement ce que j’ai constaté en surveillant mon outil nvtop.
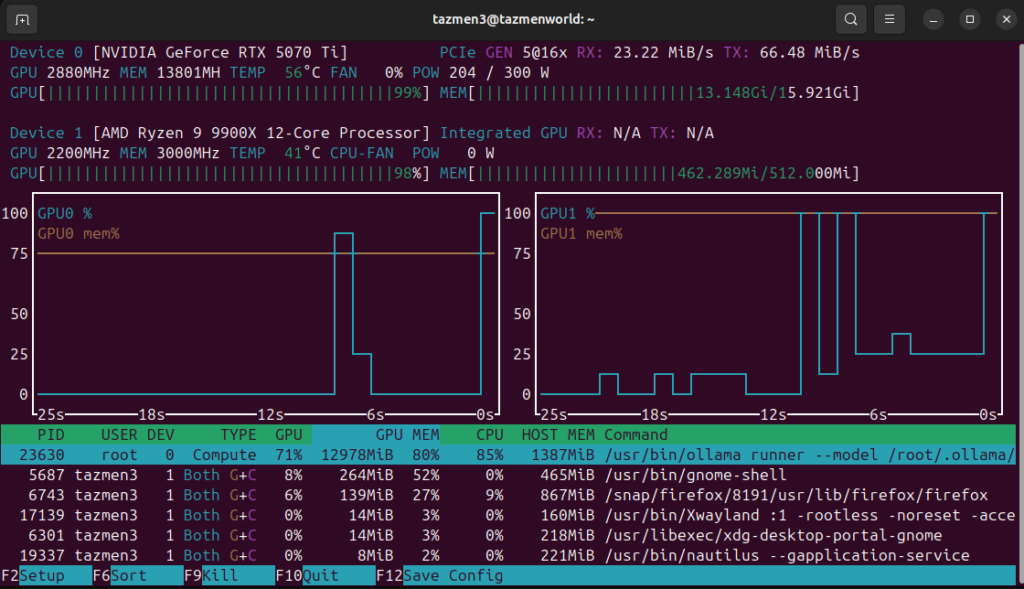
Bilan de performance
Après plusieurs jours d’utilisation intensive, voici mon constat :
- Rapidité : Sur ma machine (Ryzen 9 9900X et RTX 5070 Ti), la génération est quasi instantanée après la phase de recherche web qui prend environ 2 secondes.
- Pertinence : En passant à 5 sources de recherche au lieu de 3, j’ai éliminé la majorité des réponses incomplètes que j’avais au début de mes tests.
- Confidentialité : C’est le point de rupture total avec les solutions cloud. Je peux poser des questions sur des codes sources privés ou des documents sensibles sans aucune crainte.
[CODE : exemple_reponse_sourcee.json]
{
"question": "Dernière version stable de SearXNG ?",
"reponse": "La version actuelle est disponible sur GitHub...",
"sources": [
{"titre": "SearXNG Releases", "url": "https://github.com/searxng/searxng/releases"},
{"titre": "Documentation officielle", "url": "https://docs.searxng.org/"}
]
}En résumé, remplacer Perplexity n’est pas seulement une déclaration d’indépendance ; c’est un gain réel en précision et en tranquillité d’esprit pour quiconque prend ses données au sérieux.
VIII. Conclusion : Le bilan de la liberté
Après avoir parcouru ce long chemin de configuration, de réglages de fichiers YAML et de tests de requêtes, je me pose souvent la question : est-ce que le jeu en vaut la chandelle ? La réponse, pour moi, est un grand « oui ».
Remplacer Perplexity par une solution locale n’est pas seulement un défi technique gratifiant. C’est un acte de reprise de contrôle. En voyant ma RTX 5070 Ti grimper à 79% de charge pour synthétiser en quelques secondes une réponse complexe, je ressens une satisfaction que seul le « fait maison » peut procurer.
Performance vs Praticité : L’heure du bilan
Si l’on regarde froidement les chiffres, voici ce que je retiens de ma Tazmen Station face aux solutions propriétaires :
- Vie privée : C’est la victoire par K.O. Aucune de mes données ne quitte mon réseau local. SearXNG agit comme un bouclier impénétrable entre mes intentions de recherche et les régies publicitaires.
- Vitesse : Grâce au couple Ryzen 9 9900X et GPU NVIDIA, la latence est extrêmement faible. Une fois la phase de recherche web terminée, Mistral-Nemo génère du texte à une vitesse qui n’a rien à envier aux versions payantes de GPT ou Claude.
- Coût : Certes, l’investissement matériel est là. Mais à 20 € par mois d’abonnement économisés, ma station est rentabilisée sur la durée, sans compter qu’elle me sert aussi pour d’autres tâches lourdes.
- Précision : En forçant le système à lire 5 sources via SearXNG au lieu des 3 habituelles, j’ai obtenu une profondeur d’analyse qui m’a bluffé, notamment sur les sujets de sécurité.
| Caractéristique | Perplexity (Cloud) | Mistral Local + SearXNG |
| Vie privée & Sécurité | Données traitées sur serveurs tiers (Cloud). | Souveraineté totale : aucune donnée ne quitte ton réseau local. |
| Coût mensuel | Environ 20 $ / mois pour la version Pro. | 0 € (une fois le matériel acquis). |
| Moteur de recherche | Algorithme propriétaire (boîte noire). | SearXNG : Agrégateur anonyme et transparent (Bing, Google, Brave, etc.). |
| Contrôle du RAG | Limité aux réglages de l’interface. | Maîtrise totale du nombre de sources (ex: 5 sources) et du filtrage. |
| Matériel requis | Une simple connexion internet. | GPU dédié (RTX 5070 Ti) et CPU performant (Ryzen 9 9900X). |
| Dépendance | Dépend de la connexion et de la stabilité du service tiers. | Autonomie complète : fonctionne même hors-ligne (hors recherche web). |
| Modèles de langage | Modèles imposés (GPT-4, Claude, etc.). | Liberté de choix et de mise à jour (ex: Mistral-Nemo 12B). |
| Performance (Inférence) | Variable selon la charge des serveurs distants. | Quasi instantanée sur GPU local (13 Go de VRAM mobilisés). |
Et quoi après ?
Ce guide n’est que le début. Avec cette infrastructure Docker solide, je peux maintenant explorer de nouveaux horizons. L’étape suivante pour moi sera d’intégrer des agents autonomes capables d’exécuter des tâches encore plus complexes à partir de mes recherches web.
Bâtir sa propre IA, c’est accepter de passer un peu de temps dans son terminal pour gagner une liberté qui n’a pas de prix. J’espère que ce guide vous aura donné les clés pour, vous aussi, transformer votre machine Ubuntu en une forteresse d’intelligence privée.
[CODE : commande_finale_restart.sh]
# Pour relancer l'ensemble après une mise à jour des modèles
sudo docker compose down && sudo docker compose up -d --remove-orphansMerci de m’avoir suivi dans cette exploration technique. Si vous avez des questions sur la configuration de votre GPU ou sur les subtilités de SearXNG, n’hésitez pas à partager vos retours. La route vers l’IA locale est vaste, et nous ne faisons que commencer à en dessiner les contours.
A bientôt Louis 🐇 🤜 🤛 🐰