
Je fais tourner un agent autonome (Hermes Agent de Nous Research) sur un mini PC dédié à la maison. Jusqu’à cette semaine, toutes ses requêtes LLM passaient par OpenRouter, avec DeepSeek V4 Flash comme modèle par défaut.
OpenRouter, c’est pratique : une seule clé, des dizaines de modèles, paiement à l’usage. Mais le paiement à l’usage a un défaut quand on laisse tourner un agent : on ne sait jamais à l’avance ce qu’on va payer.
J’ai regardé mes chiffres. Ils m’ont décidé.
Les chiffres qui font mal
Sur 2 jours d’utilisation, voici ce que mon dashboard OpenRouter affichait :
| Modèle | Coût | Requêtes | Tokens |
|---|---|---|---|
| DeepSeek V4 Flash | 2,31 $ | 861 | 36 M |
| DeepSeek V4 Pro | 1,40 $ | 13 | ~1,8 M |
| Total | 3,71 $ | 874 | 37,8 M |
Deux choses sautent aux yeux.
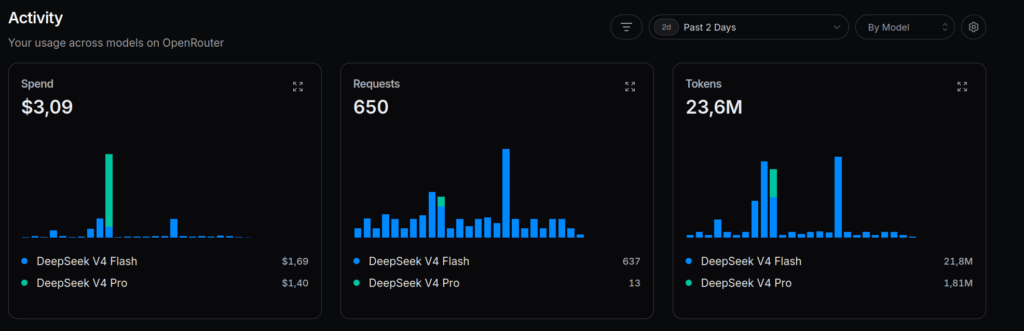
D’abord, 3,71 $ en deux jours. Si je projette ça sur un mois, je tourne autour de 55 $. C’est beaucoup pour un agent perso.
Ensuite, le détail qui m’a le plus surpris : DeepSeek V4 Pro. 13 requêtes seulement, mais 1,40 $ soit près de 40 % de ma facture pour 1,5 % de mes appels. Ces quelques requêtes lourdes que l’agent décide de router vers un gros modèle, on ne les voit pas venir. Et c’est exactement là que le paiement à l’usage devient imprévisible.
OpenCode Go : le coût fixe
OpenCode Go, c’est un abonnement à 10 $/mois (5 $ le premier mois) qui donne accès à une douzaine de modèles open source curatés : DeepSeek V4 Flash et Pro, Qwen3, Kimi K2, GLM-5, MiniMax, MiMo.
Le point clé pour moi : l’endpoint est compatible OpenAI. Pas besoin d’utiliser l’outil OpenCode lui-même. On branche la clé sur n’importe quel agent qui parle à une API LLM/Hermes dans mon cas.
La migration, étape par étape
Bonne surprise : Hermes supporte OpenCode Go nativement. La section est déjà prévue dans le fichier de config. La bascule m’a pris cinq minutes.
1. Récupérer la clé OpenCode Go
Après abonnement sur opencode.ai/go, la clé API se récupère depuis le dashboard. Elle commence par sk-.
2. Ajouter la clé dans le .env
Le fichier d’environnement de Hermes se trouve dans ~/.hermes/.env. On y décommente la ligne dédiée à OpenCode Go et on colle la clé :
bash
OPENCODE_GO_API_KEY=sk-votre-cle-iciÀ noter : on peut laisser l’ancienne clé OpenRouter en place. Hermes utilise le provider défini dans la config, pas celui dont la clé est présente. Pratique pour revenir en arrière sans rien réécrire.
3. Pointer Hermes sur OpenCode Go
Trois commandes suffisent. On change le provider, l’URL de base, et le modèle par défaut :
bash
hermes config set model.provider opencode-go
hermes config set model.base_url https://opencode.ai/zen/go/v1
hermes config set model.default opencode-go/deepseek-v4-flashJe garde le même modèle (DeepSeek V4 Flash), je change juste le tuyau qui y mène.
4. Vérifier depuis Telegram
Mon Hermes est piloté en partie via Telegram. La commande /model affiche la configuration courante et permet de changer de provider à la volée. C’est le moyen le plus rapide de confirmer que la bascule a pris.
Et le résultat une fois le modèle sélectionné :
C’est fait. L’agent tourne désormais entièrement sur OpenCode Go.
Le calcul, sans enjoliver
| Sur 2 jours | Projeté sur ~30 jours | |
|---|---|---|
| OpenRouter (réel) | 3,71 $ | ~55 $ |
| OpenCode Go (fixe) | — | 10 $ |
Sur le papier, c’est 80 % d’économie. Mais je veux être honnête sur deux nuances, parce que c’est facile de vendre du rêve avec ce genre de tableau.
Nuance 1 : mes deux jours étaient atypiques. J’étais en plein build de mon serveur d’automation, avec des sessions très denses. Mon usage courant est plus léger. Donc les 55 $ projetés sont un plafond, pas une moyenne.
Nuance 2 : OpenCode Go n’est pas illimité. Les limites sont exprimées en valeur dollar, pas en nombre de requêtes, et elles se rechargent toutes les 5 heures. Les modèles plus légers durent plus longtemps que les gros. Si vous balancez du DeepSeek V4 Pro en continu, vous taperez le plafond. Pour un usage agent normal sur un modèle Flash, ça passe largement.
Autrement dit : l’économie est réelle, mais elle suppose un usage qui rentre dans les limites du forfait. Ce n’est pas une licence pour consommer sans compter.
Ce que je retiens
Le vrai gain, ce n’est pas seulement le prix. C’est la prévisibilité. Je sais que je paie 10 $ ce mois-ci, point. Plus de facture qui dérape à cause de quelques requêtes routées vers un modèle premium sans que je l’aie demandé.
Pour un agent qui tourne 24/7 sur du matériel perso, c’est exactement ce que je cherchais : un coût plat, une seule clé, et assez de modèles pour ne jamais être bloqué.
Je n’abandonne pas OpenRouter pour autant
Important : OpenCode Go remplace OpenRouter pour le cerveau texte de mon agent, pas pour tout le reste. Je garde OpenRouter en parallèle, et il garde tout son sens pour des usages plus spécialisés : le TTS, la génération d’image et la génération de vidéo. C’est devenu un vrai hub multimodal, là où le paiement à l’usage reste le bon modèle, on ne génère pas une vidéo toutes les cinq minutes.
En vidéo justement, je travaille beaucoup en local sur ma machine principale (ComfyUI, GPU dédié). LTX et Wan sont d’excellents modèles open source, largement suffisants pour la plupart de mes besoins, et gratuits une fois le matériel amorti.
Mais soyons honnêtes : quand je veux le résultat au-dessus du lot, un Seedance 2.0 reste exceptionnel. C’est là que le cloud garde l’avantage pour ces générations ponctuelles où la qualité prime sur le coût. D’où l’intérêt de garder une porte ouverte sur OpenRouter, qui donne accès à ce genre de modèle sous la même clé.
La bonne architecture, pour moi, n’est donc pas « tout cloud » ni « tout local ». C’est : OpenCode Go pour le LLM de l’agent (coût fixe, prévisible), le local pour le gros du multimodal (LTX, Wan), et OpenRouter en appoint pour le TTS et les générations haut de gamme comme Seedance 2.0.
En résumé
Si votre conso OpenRouter en LLM dépasse régulièrement 10 $/mois, basculer le cerveau de votre agent vers OpenCode Go est vite rentable. En dessous, restez sur le paiement à l’usage vous paierez moins. Et dans les deux cas, gardez OpenRouter sous la main pour ce qu’il fait désormais très bien : le multimodal à la demande.