
Soyons clairs dès le départ : je n’utilise pas ElevenLabs au quotidien. La qualité est au sommet du marché, le clonage de voix est bluffant, et le multilingue tient parfaitement le français. Difficile de faire mieux côté rendu. Mais pour mon usage, l’abonnement est tout simplement trop cher au regard de ce que j’en ferais réellement.
Le souci, c’est qu’il m’arrive ponctuellement d’en avoir besoin. Une voix off propre pour une vidéo, un test de clonage, une narration pour un article. Et là, deux choses bloquent. La première, c’est le modèle économique. ElevenLabs fonctionne par abonnement avec un plafond de crédits, et le clonage de voix professionnel, celui qui donne le meilleur résultat, démarre à 22 dollars par mois sur le plan Creator. Le plan gratuit, lui, interdit tout usage commercial et impose une mention ElevenLabs dans tes productions, ce qui le rend inutilisable pour de la monétisation YouTube. Payer un abonnement mensuel pour un besoin occasionnel, ça n’a aucun sens.
La deuxième, c’est la confidentialité. Pour cloner ma propre voix, je dois envoyer un échantillon de ma voix sur les serveurs d’une société américaine. Or ta voix, c’est une donnée biométrique. C’est ce qu’il y a de plus personnel, au même titre qu’une empreinte digitale.
Alors j’ai fait ce que je fais à chaque fois : j’ai décidé de rapatrier la capacité sur ma propre machine. L’objectif est simple. Avoir à disposition, à tout moment, une synthèse vocale française avec clonage de voix de qualité, sans abonnement, sans plafond, et sans que ma voix ne quitte mon réseau local. Je te préviens tout de suite : sur une carte Blackwell comme la RTX 5070 Ti, l’installation par défaut plante. Et le contournement n’est documenté nulle part en français. Voici donc le parcours complet, pièges compris.
I. La quête de la souveraineté vocale
Pourquoi se compliquer la vie quand un service à 22 dollars par mois fait le travail ? La réponse tient en deux mots : maîtrise et confidentialité. En produisant mes voix sur ma propre station, je ne dépends plus d’un quota de crédits, d’une connexion internet ou d’une politique de conservation que je ne contrôle pas. Et mon échantillon vocal reste chez moi, sur mon disque.
Le moteur de tout ça, c’est XTTS, le modèle de synthèse vocale de Coqui. Il fait du clonage de voix zero-shot multilingue, français inclus. Tu lui donnes 10 à 30 secondes d’un échantillon, il génère ensuite n’importe quel texte avec cette voix. Pour le piloter, j’utilise AllTalk, un serveur qui enrobe XTTS avec une API compatible OpenAI, une interface web, et la gestion de plusieurs moteurs. C’est le projet d’erew123 sur GitHub.
Ma configuration repose sur le matériel de ma Tazmen Station : un processeur AMD Ryzen 9 9900X épaulé par une carte NVIDIA GeForce RTX 5070 Ti avec 16 Go de VRAM. Bonne nouvelle, XTTS en inférence ne mobilise qu’environ 4 Go de VRAM. Tu as donc largement la place de le faire cohabiter avec un modèle de langage ou de la génération d’images sur la même carte.
Le hic, c’est que la 5070 Ti est une carte Blackwell. Et c’est exactement là que l’aventure commence.
II. Le piège Blackwell
C’est le point qui fait abandonner la moitié des gens, alors autant l’attaquer en premier.
L’installation d’AllTalk pose du PyTorch compilé pour CUDA 12.1. Ce build connaît les architectures GPU jusqu’à sm_90, c’est-à-dire la génération Hopper. Il ne connaît pas le sm_120 de Blackwell. Résultat concret : au premier chargement du modèle sur le GPU, c’est le crash immédiat.
Le contournement consiste à remplacer PyTorch par une version CUDA 12.8, qui elle gère Blackwell. En pratique, torch 2.7.0 avec torchvision et torchaudio alignés sur la même version et le même canal cu128.
Attention au piège dans le piège. Si tu installes torch et torchaudio sans verrouiller les versions, pip te choisit un torchaudio incompatible et tu te manges une erreur de symbole au démarrage du type undefined symbol: torch_library_impl. Il faut imposer les trois versions ensemble, dans l’environnement Python d’AllTalk, une fois l’installation de base terminée :
[CODE : fix_blackwell_cu128.sh]
pip install torch==2.7.0 torchvision==0.22.0 torchaudio==2.7.0 --index-url https://download.pytorch.org/whl/cu128La vérification immédiate, et celle qui doit devenir un réflexe, c’est de confirmer que le GPU est bien vu :
[CODE : verif_gpu.sh]
python -c "import torch; print(torch.__version__, torch.cuda.is_available(), torch.cuda.get_device_name(0))"Tu dois obtenir 2.7.0+cu128, True, et le nom de ta carte. Si tu as ça, le sm_120 est géré et le plus dur est derrière toi.

III. L’installation : attention à la branche
Première erreur que j’ai commise, et que tu vas éviter. Le git clone standard tire la branche master, qui correspond à AllTalk V1. La V1 n’a pas d’interface graphique complète, pas de RVC, et son API renvoie les URLs dans un format différent qui casse l’intégration avec certains outils. J’ai perdu un bon moment dessus avant de comprendre.
La version que tu veux, la V2, vit sur la branche alltalkbeta. La nuance n’est écrite nulle part de façon évidente, alors note la bien :
[CODE : install_alltalk_v2.sh]
git clone -b alltalkbeta https://github.com/erew123/alltalk_tts
cd alltalk_tts
chmod +x atsetup.sh
./atsetup.shTu choisis l’option Standalone Application, puis l’installation de base. Le script crée un environnement Python isolé et tire toutes les dépendances. C’est long, laisse mouliner.
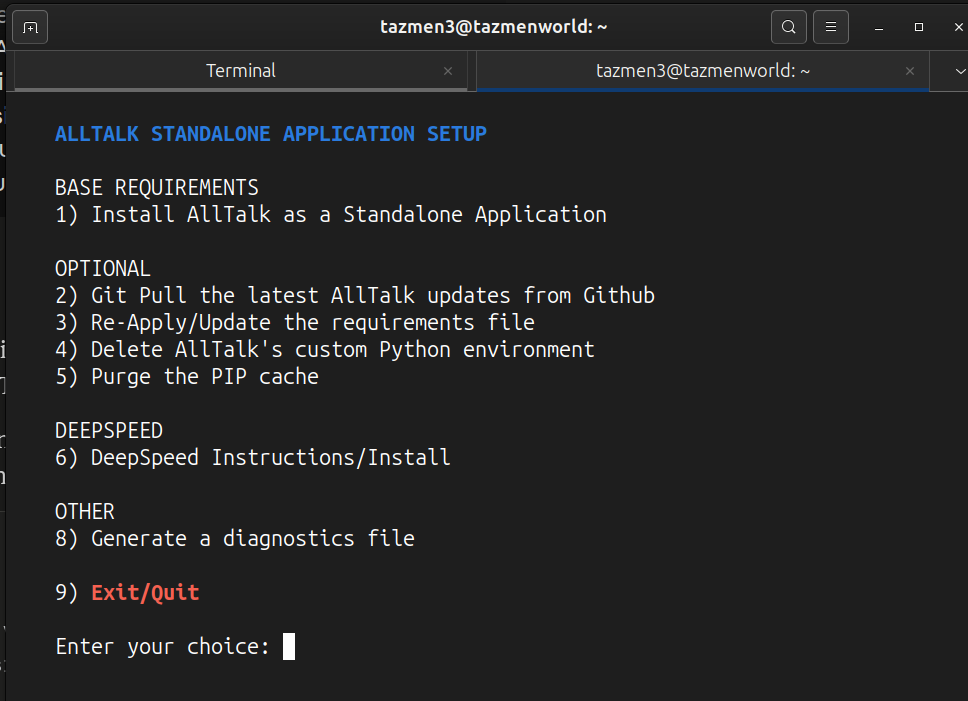
Deux avertissements qui m’ont coûté du temps. Au premier lancement, un compte à rebours de 60 secondes télécharge un modèle Piper par défaut. Si tu ne fais rien, tu te retrouves avec Piper, qui est un moteur correct mais sans clonage de voix. Choisis bien le moteur xtts dans le menu de démarrage. Et surtout, ne lance jamais AllTalk en root, sinon ton environnement Python se retrouve avec des fichiers root-owned et tu galères ensuite à chaque commande.
IV. Les correctifs de dépendances
Le remplacement de PyTorch chamboule l’arbre des dépendances. Trois ajustements à faire, et un bug propre à la branche beta à corriger.
Premier point, setuptools. La réinstallation de torch monte setuptools en version récente, qui a supprimé le module pkg_resources. Sauf que la version de librosa embarquée par XTTS en a encore besoin. Sans ça, crash au démarrage avec ModuleNotFoundError: No module named 'pkg_resources'. Le correctif tient en une ligne :
[CODE : fix_setuptools.sh]
pip install "setuptools<81"Deuxième point, les dépendances système. Le log d’AllTalk te signale trois manques. Le plus important, c’est espeak-ng : XTTS s’en sert pour la phonémisation, ce n’est pas optionnel. Les deux autres relèvent du confort, ffmpeg pour le transcodage des sorties audio et libaio pour faire taire un avertissement :
[CODE : fix_deps_systeme.sh]
sudo apt install espeak-ng ffmpeg libaio-devTroisième point, un bug propre à la V2 beta. Quand tu changes de moteur depuis l’interface, le code tente un appel chaîné change_engine(...).save() qui plante avec une AttributeError, parce que la méthode ne renvoie pas l’objet attendu. On sépare proprement les deux appels :
[CODE : patch_change_engine.sh]
sed -i 's/tts_engines_config.change_engine(requested_engine).save()/tts_engines_config.change_engine(requested_engine)\n tts_engines_config.save()/' ~/alltalk_tts/tts_server.pyUne note de dépannage utile. Sur la V1, j’avais aussi dû patcher le chargement des modèles à cause du passage de PyTorch 2.6 en weights_only=True par défaut, qui refuse les classes personnalisées de Coqui. Sur la V2, le fork de coqui-tts gère déjà ce cas et le modèle charge sans rien toucher. Si jamais tu vois une UnpicklingError au chargement, c’est ce point précis qu’il faut corriger.
V. Le modèle XTTS et le basculement de moteur
Si le moteur xtts est sélectionné mais que le modèle n’a jamais été téléchargé, AllTalk cherche le dossier models/xtts/ et ne trouve rien. Tu télécharges le modèle, soit depuis l’onglet TTS Engines Settings de l’interface, soit en ligne de commande depuis le dépôt officiel sur Hugging Face :
[CODE : telecharger_modele_xtts.sh]
mkdir -p ~/alltalk_tts/models/xtts/xttsv2_2.0.3
cd ~/alltalk_tts/models/xtts/xttsv2_2.0.3
wget https://huggingface.co/coqui/XTTS-v2/resolve/main/model.pth
wget https://huggingface.co/coqui/XTTS-v2/resolve/main/config.json
wget https://huggingface.co/coqui/XTTS-v2/resolve/main/vocab.json
wget https://huggingface.co/coqui/XTTS-v2/resolve/main/speakers_xtts.pth
wget https://huggingface.co/coqui/XTTS-v2/resolve/main/dvae.pth
wget https://huggingface.co/coqui/XTTS-v2/resolve/main/mel_stats.pthCompte environ 2 Go au total, le fichier model.pth faisant à lui seul près de 1,8 Go. Ensuite, dans l’interface, onglet Generate TTS, tu passes Available Engines sur xtts puis tu cliques Change Model.
L’interface web d’AllTalk est accessible sur le port 7852, et l’API sur le port 7851. C’est cette API compatible OpenAI qui te permettra ensuite de brancher XTTS sur tes propres scripts ou sur n8n.
Côté performance, sur ma RTX 5070 Ti, le modèle charge en 5 à 6 secondes. Et la génération tape entre 0,2 et 0,5 seconde pour une phrase courte. C’est largement sous le temps réel, et franchement comparable à ce que je constatais sur ElevenLabs, sans la latence réseau.
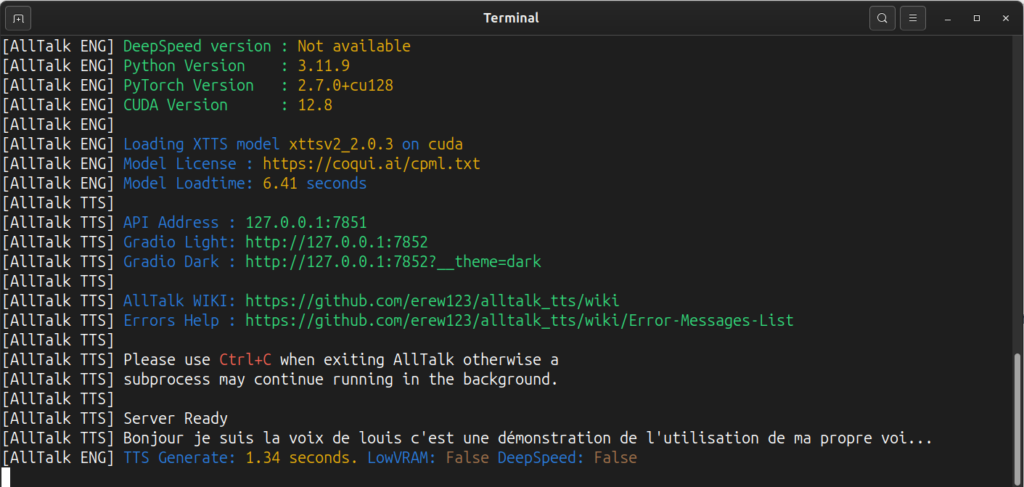
VI. Cloner sa voix : tout se joue sur l’échantillon
C’est le coeur du sujet, et c’est aussi là que tout le monde se plante. Le clonage XTTS est aussi bon que ton échantillon. Ni plus, ni moins. Un clone moyen vient presque toujours d’un sample bâclé, pas du modèle.
Les règles à respecter pour un bon échantillon :
- Format mono, 22050 Hz, 16 bits.
- Durée de 10 à 30 secondes. Au-delà de 60 secondes, la qualité ne s’améliore plus et l’encodage ralentit.
- Voix francophone si tu veux du français propre. Un locuteur anglophone clone un accent anglais sur ton texte français.
- Aucun bruit de fond, aucune respiration bruyante, aucun raclement de gorge, aucun silence en début ou en fin.
- Ton naturel et neutre. Si ton sample est joyeux ou agressif, le clone le sera aussi.
Une parenthèse cybersécurité qui devrait te faire réfléchir, parce que ce chiffre n’est pas anodin. 10 à 30 secondes de voix suffisent à produire un clone convaincant. C’est exactement pour cette raison qu’il ne faut jamais parler en premier quand tu reçois un appel suspect ou un numéro inconnu. Un simple « allô, oui, qui est à l’appareil ? » peut donner à un escroc assez de matière pour cloner ta voix, et s’en servir ensuite pour piéger un proche au téléphone, par exemple en simulant un appel de détresse. Le réflexe à prendre : laisse l’interlocuteur se présenter d’abord, et ne meuble pas le silence. La technologie qui te sert dans cet article peut tout aussi bien servir contre toi.
Pour nettoyer un enregistrement, Audacity fait parfaitement le travail. Tu importes ton fichier, tu sélectionnes un passage de silence, puis Effect, Noise Reduction, Get Noise Profile, et tu appliques la réduction sur l’ensemble. Tu coupes les respirations à la souris, tu normalises à -3 dB, et tu exportes en WAV mono 22050 Hz 16 bits.
Si tu veux juste convertir un fichier existant au bon format, ffmpeg suffit :
[CODE : convertir_sample.sh]
ffmpeg -i source.mp3 -ar 22050 -ac 1 -sample_fmt s16 ~/alltalk_tts/voices/mavoix.wavTu déposes le fichier dans le dossier ~/alltalk_tts/voices/, tu cliques Refresh Settings dans l’interface, et ta voix apparaît dans la liste. Sélectionne la, tape une phrase de test, et écoute le résultat.dans l’interface, et votre voix apparaît dans la liste. Sélectionnez la, tapez une phrase de test, et écoutez le résultat.
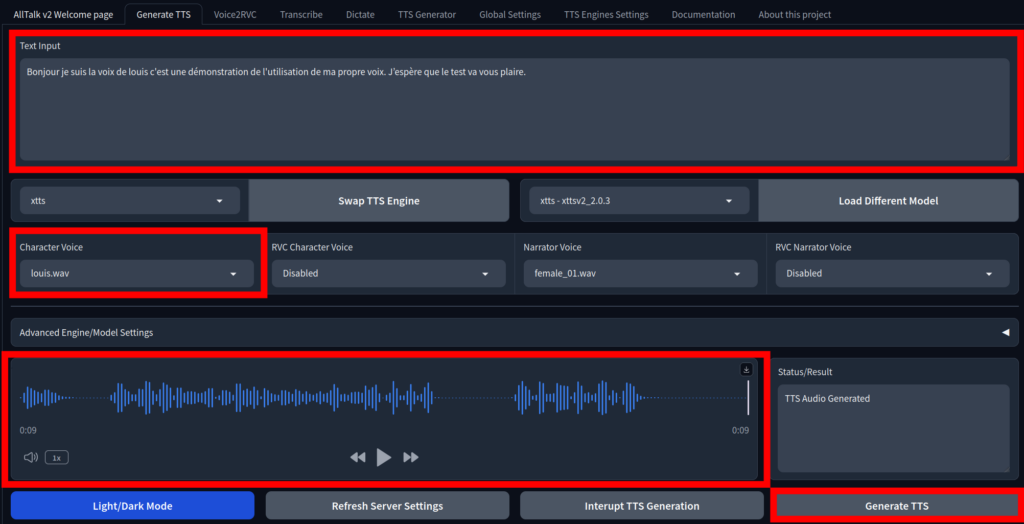
Voici le résultat 😀
VII. Affiner le rendu
Si le clone n’est pas à la hauteur malgré un bon échantillon, deux réglages dans l’onglet Generate TTS.
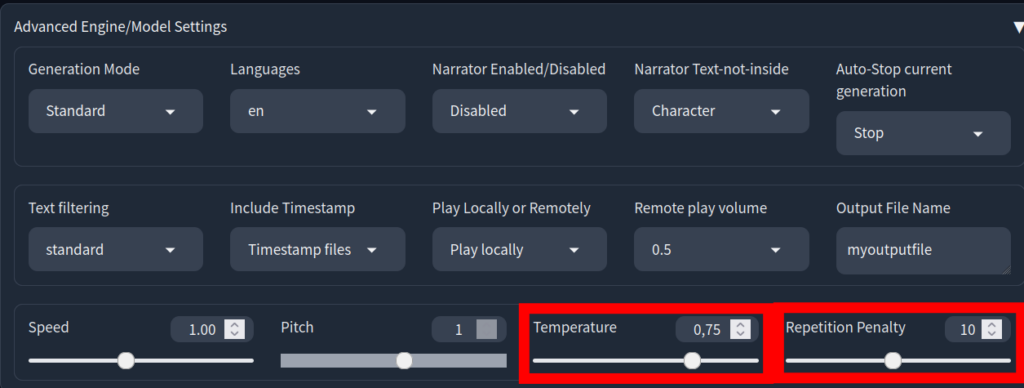
La température. Plus elle est basse, entre 0,5 et 0,65, plus le rendu colle à ton sample. Plus elle est haute, entre 0,75 et 0,85, plus c’est expressif, mais ça peut dériver.
La repetition penalty. La valeur par défaut à 10 est extrême. Descends à 2 ou 3 pour un rendu nettement plus naturel.
Si ça ne suffit toujours pas, deux options plus lourdes existent. Le mode multi-sample, où tu fournis plusieurs fichiers WAV d’une même personne pour stabiliser le clone. Et le fine-tuning, où tu entraînes réellement XTTS sur ta voix avec 2 à 20 minutes d’audio propre, pour obtenir un modèle dédié bien supérieur au zero-shot. Sur une 5070 Ti, cet entraînement prend une demi-heure environ. Je détaillerai cette partie dans un article séparé, parce qu’elle mérite son propre guide.
VIII. Les cas d’usage concrets
Une fois XTTS en place, ça ouvre plusieurs workflows qui remplacent directement ce que je faisais sur ElevenLabs :
- Voix off pour mes vidéos YouTube. J’écris le script, je génère les pistes avec ma voix clonée, je monte dans mon éditeur. Zéro crédit consommé.
- Lecture audio de mes articles de blog. Via l’API d’AllTalk branchée sur n8n, je génère automatiquement une version audio de chaque article.
- Génération de faux podcasts. Un modèle de langage local écrit un dialogue à deux voix, XTTS le synthétise avec deux échantillons différents.
- Doublage de mes propres vidéos en français. C’est le pipeline le plus puissant. On chaîne une transcription avec Whisper, une traduction avec un modèle local, puis une régénération en français avec ma propre voix.
Chacun de ces workflows mérite son propre tutoriel, et j’y reviendrai dans la suite de cette série.
Voici un exemple en anglais:
en espagnole:
En allemand:
est ça entre très bien dans un workfload n8n
IX. Démarrage automatique avec systemd
Pour ne pas relancer le serveur à la main à chaque démarrage, un service systemd. Tu crées le fichier /etc/systemd/system/alltalk.service :
[CODE : alltalk.service]
[Unit]
Description=AllTalk TTS Server
After=network.target
[Service]
Type=simple
User=ton_user
WorkingDirectory=/home/ton_user/alltalk_tts
ExecStart=/home/ton_user/alltalk_tts/start_alltalk.sh
Restart=on-failure
RestartSec=10
[Install]
WantedBy=multi-user.targetPuis tu l’actives :
[CODE : activer_service.sh]
sudo systemctl daemon-reload
sudo systemctl enable alltalk
sudo systemctl start alltalkAllTalk démarre désormais au boot, en arrière plan, avec relance automatique en cas de crash. Un détail qui m’a piégé deux fois : à l’arrêt manuel, le sous-process moteur a tendance à survivre et à garder le port 7851 occupé, ce qui bloque le redémarrage. Avant de relancer, vérifie avec lsof -i:7851 que le port est libre, et au besoin libère le avec kill $(lsof -t -i:7851).
X. Conclusion : le bilan de la liberté
Après ce parcours de correctifs et de réglages, est-ce que le jeu en vaut la chandelle ? Pour moi, c’est un oui franc.
Soyons lucides, ElevenLabs garde une longueur d’avance sur la qualité brute, surtout sur les nuances émotionnelles les plus fines. Mais XTTS en local atteint un niveau largement suffisant pour de la voix off, du doublage et de la lecture d’articles. Et il le fait sans abonnement, sans plafond de crédits, et sans que ma voix ne quitte ma machine. Pour quelqu’un qui prend ses données au sérieux, c’est le point de rupture.
Voici comment je résume la comparaison après plusieurs jours d’utilisation :
| Caractéristique | ElevenLabs (Cloud) | XTTS Local + AllTalk |
|---|---|---|
| Vie privée & biométrie | Échantillon vocal envoyé sur serveurs tiers (US) | Souveraineté totale, ta voix ne quitte pas ton réseau |
| Coût mensuel | À partir de 22 $/mois pour le clonage pro | 0 € une fois le matériel acquis |
| Quota | Plafond de crédits, payé que tu l’atteignes ou non | Génération illimitée |
| Droits commerciaux | Plan gratuit interdit + attribution imposée | Aucune restriction, aucune mention obligatoire |
| Qualité | Référence du marché, nuances émotionnelles au top | Très bonne, suffisante pour la majorité des usages |
| Matériel requis | Une simple connexion internet | GPU dédié (RTX 5070 Ti, 16 Go de VRAM) |
| Clonage de voix | Instantané et professionnel | Zero-shot, et fine-tuning possible en local |
| Dépendance | Dépend du service et de la connexion | Autonomie complète, fonctionne hors ligne |
L’installation n’est pas plug and play sur une carte Blackwell, je ne vais pas te mentir. Mais une fois les correctifs passés, c’est stable, rapide, et entièrement à toi. Le plus gros levier de qualité reste l’échantillon : un bon enregistrement propre vaut tous les réglages du monde.
Dans le prochain article de cette série, je détaille les workflows en profondeur : la voix off, la lecture d’articles via n8n, le faux podcast, et surtout le doublage de mes propres vidéos YouTube en chaînant Whisper, traduction et XTTS. La route vers l’IA locale est encore longue, et on continue à en dessiner les contours.
A bientôt Louis 🐇 🤜 🤛 🐰