
Depuis quelque temps, je vois passer pas mal d’articles sur l’IA locale ou dans du cloud, et souvent la même idée revient : jouer sur le contexte. Charger une grosse fenêtre de contexte pour « fixer l’état » du modèle, cadrer son comportement et orienter le type de réponse qu’il va te sortir. L’intention est bonne donner au modèle un maximum de matière pour qu’il réponde juste.
Le problème, c’est que ça part souvent dans le mur. Plus le contexte augmente, plus on tombe dans ce qu’on appelle le Lost in the Middle : le modèle finit par perdre l’info au milieu de tout ce qu’on lui a donné. C’est ce que je veux t’expliquer ici, simplement et voir pourquoi, dans la plupart des cas, un RAG (Retrieval-Augmented Generation) fait le boulot bien mieux qu’un gros contexte.
1. Le réflexe « balance tout, il triera »
Coller 800 pages dans la fenêtre et poser sa question, c’est tentant parce que c’est rapide à mettre en place. Pas de base vectorielle, pas de chunking, pas d’embeddings à calculer.
Le souci, c’est qu’on mélange deux choses : la capacité (combien de tokens le modèle accepte en entrée) et l’attention utile (ce qu’il sait réellement exploiter là-dedans). Avoir 16 Go de VRAM ne veut pas dire qu’on les utilise bien souviens-toi de la « taxe d’affichage » Windows. Pour le contexte, c’est le même principe.
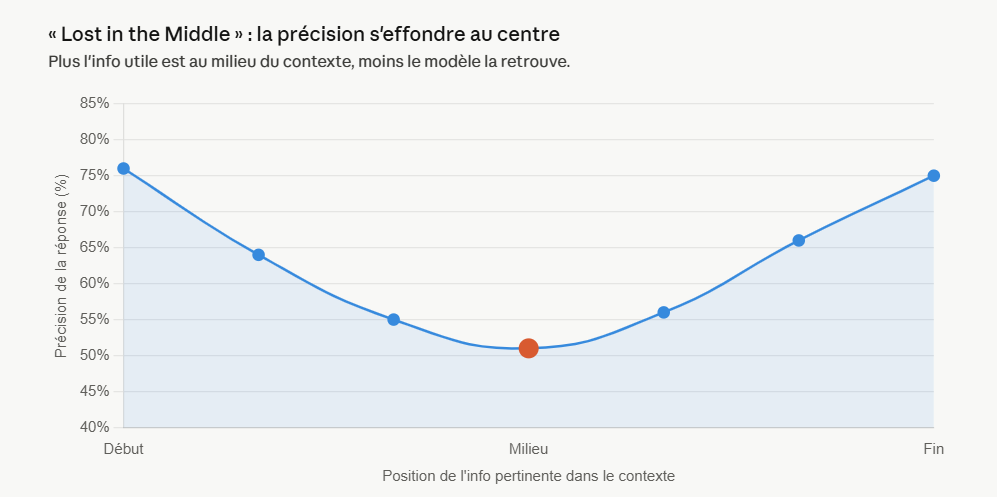
2. « Lost in the Middle » : l’info au milieu passe à la trappe
Le papier de référence sur le sujet, c’est Lost in the Middle: How Language Models Use Long Contexts (Liu et al., arXiv:2307.03172). Son constat : quand l’information pertinente est placée au milieu d’un long contexte, le modèle la retrouve mal.
La performance suit une courbe en U. Le modèle exploite bien ce qui est en début et en fin de contexte, et décroche au centre. Autrement dit, ta réponse peut être présente noir sur blanc dans les tokens que tu as fournis, et passer à côté juste parce qu’elle est tombée au mauvais endroit. Pour quelqu’un qui automatise des workflows, c’est un vrai problème : l’info est là, mais le résultat est faux.
3. Le « context rot » : plus c’est gros, plus ça hallucine
« Lost in the middle » est la partie la plus connue. Il existe un phénomène plus large, baptisé context rot : la qualité des réponses baisse à mesure que le contexte s’allonge, et ça commence avant que la fenêtre soit pleine.
Une étude de Chroma a testé 18 modèles récents. Tous se dégradent quand l’entrée s’allonge ; un modèle à 200K tokens peut déjà perdre en qualité dès 50K. Ce n’est donc pas la capacité qui compte, mais le rapport signal/bruit.
Deux mécanismes l’expliquent :
- La dilution de l’attention. L’attention « soft » d’un Transformer a une capacité fixe. Plus tu ajoutes de tokens, plus elle s’étale sur du bruit, et moins chaque token utile en reçoit. C’est architectural aucun prompt ne le contourne.
- Les hallucinations. Noyé dans la masse, le modèle comble les trous en inventant, avec le même aplomb que d’habitude.
L’analogie infra, c’est le spillover VRAM dont je parlais dans la série VRAM Tuning : tant que tout tient, ça file à ~1000 Go/s ; dès que ça déborde, on tombe à ~60 Go/s. Le gros contexte fait pareil avec l’attention du modèle, sauf que tu paies en plus ces tokens à chaque requête.
4. Ce que change le RAG
Le RAG inverse la logique. Au lieu de tout donner d’un coup, on récupère en amont les passages pertinents pour la question posée, et on ne sert que ça.
Le déroulé est simple :
- La question arrive.
- Un système de récupération (base vectorielle, recherche sémantique) sort les quelques morceaux utiles de ta base de connaissances.
- On injecte seulement ces morceaux, propres et bien placés.
- Le modèle répond sur une base nette.
Les trois problèmes tombent en même temps : pas de milieu géant où se perdre, une attention concentrée sur l’utile, et un signal/bruit qui limite les hallucinations.
C’est la même logique que le headless : on garde le moteur de calcul utile, on enlève le reste. On ne charge que ce qui sert.
5. Quand le gros contexte reste pertinent
Le RAG n’est pas la réponse à tout. Le gros contexte garde du sens dans des cas précis :
- Un document unique et court à analyser en entier (un contrat de 10 pages, un fichier de code) : monter un RAG là-dessus, c’est disproportionné.
- Un raisonnement transversal qui doit croiser des infos dispersées dans tout le document (« résume l’évolution du ton sur l’ensemble du rapport ») : un RAG qui ne récupère que des bouts isolés peut manquer la vue d’ensemble.
- Le prototypage : pour un test rapide, coller dans le contexte va plus vite. À condition de savoir que ça ne tiendra pas à l’échelle.
La vraie réponse dépend de la charge. Mais en production, sur du volume, le RAG l’emporte.
Tableau comparatif : RAG vs Gros Contexte
| Critère | Gros Contexte | RAG |
|---|---|---|
| Info au milieu | Souvent ratée (courbe en U) | Toujours en tête de contexte |
| Attention du modèle | Diluée sur le bruit | Concentrée sur l’utile |
| Risque d’hallucination | Augmente avec la taille | Réduit (bon signal/bruit) |
| Coût en tokens | Élevé (et facturé) | Minimal, ciblé |
| Mise en place | Triviale (copier-coller) | Pipeline à construire |
| Passage à l’échelle | Se dégrade vite | Tient la route |
| Cas idéal | Doc unique et court, proto | Base de connaissances, prod |
Conclusion
Le gros contexte, c’est la solution rapide, et elle a un coût : ton info se perd au milieu, l’attention se dilue, et tu paies plus pour des réponses moins fiables. « Lost in the middle » l’a montré dès 2023, le context rot l’a confirmé depuis.
Le RAG demande un peu de travail en amont base vectorielle, chunking, embeddings. Mais c’est la même logique que le reste du blog : ne pas gâcher la ressource, ne garder que l’utile. La capacité brute, c’est une chose ; savoir quoi mettre dedans, c’en est une autre.
On se retrouve pour la suite, où on montera un petit RAG local de bout en bout, avec une base vectorielle qui tourne sur ta machine et pas dans le cloud de quelqu’un d’autre. On va chunker, embedder et récupérer comme il faut.
Source principale : Liu et al., « Lost in the Middle: How Language Models Use Long Contexts », arXiv:2307.03172. Compléments sur le context rot et la dilution de l’attention : recherches Chroma (2025) et travaux associés sur la dégradation en long contexte.