
Introduction
Noël est passé, le papier cadeau est à la poubelle, et pour les plus chanceux d’entre vous, une boîte verte et noire trône désormais dans le PC. Peut-être que le Père Noël a été d’une générosité indécente avec une RTX 4090 ou la mythique RTX 5090 :OOO. D’autres, plus raisonnables (ou comme moi, avec un budget d’ingénieur réaliste), ont déballé une 5070 Ti 16 Go.
C’est une belle pièce de silicium, mais j’ai une mauvaise nouvelle si vous êtes sous Windows : vous l’utilisez mal.
En plus, soyons honnêtes un instant : Windows 11, c’est un peu le Windows Millennium des années 2025 (les « vieux cons » comme moi comprendront la douleur de cette référence).
Dans le monde de l’infrastructure IA locale, avoir du hardware, c’est bien. Savoir l’optimiser, c’est mieux. La majorité des utilisateurs « gâchent » une quantité astronomique de VRAM (Video RAM) simplement pour afficher leur fond d’écran. Dans cette série d’articles, dont voici la Partie 1, nous allons voir comment récupérer cette mémoire précieuse pour ce qui compte vraiment : l’entraînement et l’inférence de vos modèles, et non l’affichage de l’interface de cet OS capricieux.
1. Analyse Technique : La « Taxe d’Affichage » Windows
Pourquoi cette optimisation est-elle critique ? Parce que la VRAM est une ressource finie et non extensible. Contrairement à la RAM système où l’on peut rajouter une barrette (de toute façon vu le prix c’est mort :D), votre RTX 5070 Ti restera bloquée à 16 Go.
Dès que vous branchez un câble HDMI sur votre GPU dédié (dGPU), le sous-système graphique de Windows (WDDM – Windows Display Driver Model) s’approprie une partie de la mémoire pour gérer le DWM (Desktop Window Manager).
Le constat est technique et douloureux : Regardez cette capture d’une RTX 5070 Ti au repos, simplement connectée à un écran sous Windows.
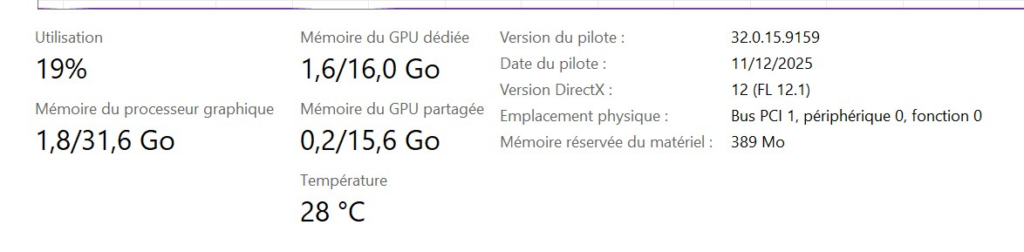
- Idle Consumption : Comme vous le voyez ci-dessus, Windows vampirise ici 1,6 Go juste pour exister.
- Impact IA : Sur un LLM, ces 1,6 Go sont la différence entre charger un modèle 13B ou crasher avec une erreur
CUDA out of memory. - Spillover : Quand la VRAM est pleine, le système déborde sur la RAM classique. On passe d’une bande passante de ~1000 Go/s à ~60 Go/s. C’est la mort des performances.
2. Impacts sur l’Infrastructure Physique (Layer 1)
L’optimisation commence par le câblage. L’objectif est de séparer les rôles : le Control Plane (Affichage OS) et le Data Plane (Calcul IA).
La stratégie du « Headless Hybride »
C’est quelque chose qui paraît logique, mais que peu de monde fait : débrancher la carte vidéo du moniteur. L’idée est d’utiliser l’iGPU (la puce graphique intégrée à votre processeur Intel ou AMD Ryzen) pour gérer l’affichage de Windows. Ainsi, votre monstre de puissance (la RTX) reste « Headless » (sans tête), 100% disponible pour PyTorch ou TensorFlow.
La gestion du flux vidéo
On ne va pas passer notre vie à quatre pattes sous le bureau pour débrancher le HDMI. La solution infra pragmatique, c’est le Switch HDMI ou le KVM.

ce type de modèle se trouve souvent dans les 20 euros
Le piège du simple débranchement
Une fois l’écran basculé sur la carte mère (iGPU) et la RTX physiquement « débranchée » (via le switch), on s’attend à récupérer 100% de la VRAM. Erreur.
Regardez ce qu’il se passe quand on coupe juste l’affichage :
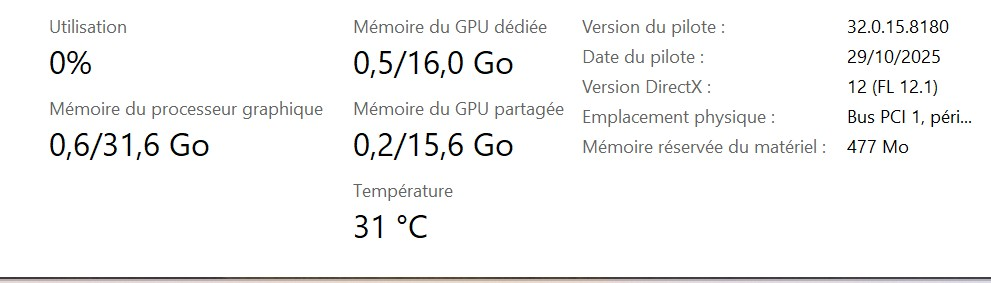
On voit bien qu’il reste 0,5 Go de mémoire fantôme utilisée. Windows garde la carte « prête à dégainer » et certains processus d’arrière-plan (Nvidia Container, etc.) squattent toujours la mémoire. C’est là que l’automatisation logicielle devient indispensable pour aller chercher les derniers méga-octets.
3. Recommandations : Automatisation et Scripting
Une fois le câble géré, il faut nettoyer la couche logicielle. Même sans écran, certains processus continuent d’allouer de la mémoire. Pour éviter de modifier le BIOS à chaque fois, j’ai développé une solution d’automatisation.
Le Script PowerShell de Bascule (Switch)
Voici le code pour votre boîte à outils SysAdmin. Il modifie le registre pour le Hardware Scheduling et désactive/active le périphérique via pnputil.
Fichier : GPU_Switch.ps1
Clear-Host
Write-Host "=== RTX 30/40/50XX Headless Switch (IA/Gaming) ===" -ForegroundColor Green
Write-Host "1: Headless ON (AI optimized - iGPU)" -ForegroundColor Cyan
Write-Host "2: Headless OFF (Gaming RTX)" -ForegroundColor Yellow
$choice = Read-Host "Choix (1/2)"
if ($choice -eq "1") {
Write-Host "→ Headless IA ON..." -ForegroundColor Green
Set-ItemProperty -Path "HKLM:\SYSTEM\CurrentControlSet\Control\GraphicsDrivers" -Name "HwSchMode" -Value 2
pnputil /disable-device "PCI\VEN_10DE*DEV_*" | Out-Null
Write-Host "Reboot en 5s... (VRAM 100% IA après)" -ForegroundColor Green
Start-Sleep 5; Restart-Computer -Force
}
elseif ($choice -eq "2") {
Write-Host "→ Gaming RTX ON..." -ForegroundColor Yellow
pnputil /enable-device "PCI\VEN_10DE*DEV_*" | Out-Null
Set-ItemProperty -Path "HKLM:\SYSTEM\CurrentControlSet\Control\GraphicsDrivers" -Name "HwSchMode" -Value 1
Write-Host "Reboot en 5s... (RTX display after)" -ForegroundColor Yellow
Start-Sleep 5; Restart-Computer -Force
} else {
Write-Host "Invalid choice!" -ForegroundColor Red; Start-Sleep 2; & $MyInvocation.MyCommand.Path
}Et j’exécute le script powershell avec un batch ou j’ai mis le raccourci sur le bureau à exécuter en administrateur :
Fichier : GPU_Switch.bat
@echo off
powershell -ExecutionPolicy Bypass -WindowStyle Maximized -File "%~dp0GPU_Switch.ps1"
pauseLe Résultat Final
Une fois le mode « Headless » activé via le script et le câble basculé sur l’iGPU, voici l’état de la même carte RTX 5070 Ti :
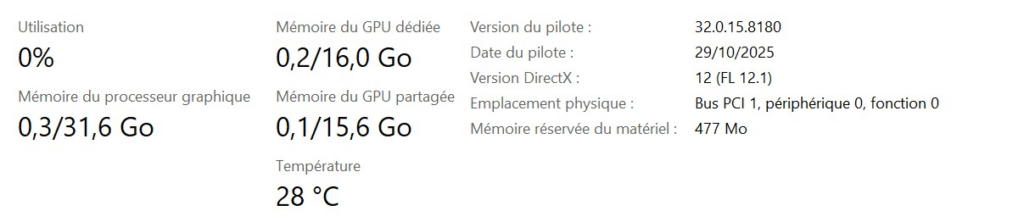
Conclusion
Conclusion et Résultats : L’Efficacité au Service de la Performance
Après avoir mis en place ces optimisations et configuré l’environnement en mode « headless » avec les scripts appropriés, les résultats sont sans appel. Cette approche ne se contente pas de libérer de la ressource brute, elle transforme radicalement le workflow d’entraînement.
1. Un Gain de Temps Majeur
L’optimisation de la gestion des ressources a un impact direct sur la rapidité d’exécution. Sur un cycle d’entraînement lourd qui nécessitait auparavant 8 heures, le temps de traitement est descendu à 5 heures. Cette réduction de près de 40 % permet d’accélérer les itérations de recherche et de développement de manière significative.
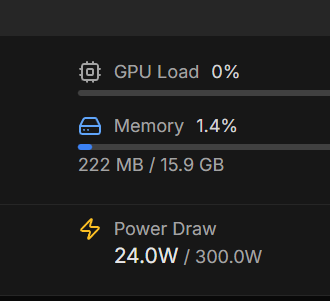
2. Libération Totale de la VRAM
L’un des plus grands défis en scripting IA est de s’assurer que les ressources sont correctement restituées au système une fois la tâche terminée. Grâce au déchargement dynamique et à la suppression des processus graphiques inutiles, l’utilisation de la VRAM retombe pratiquement à 0 % (seulement 222 Mo utilisés sur 16 Go, soit 1,4 %) dès que l’entraînement s’arrête. Cela garantit que la carte est immédiatement prête pour une nouvelle tâche sans nécessiter de redémarrage ou de nettoyage manuel des processus « zombies ».
3. Sobriété Énergétique
Enfin, la gestion thermique et électrique est optimisée. En mode veille (idle), une fois les scripts terminés, la consommation de la carte tombe sous la barre des 24W. Pour une carte de cette puissance (capable de monter jusqu’à 300W), ce niveau de consommation est extrêmement raisonnable, permettant de laisser le serveur tourner H24 sans impact écologique ou financier démesuré.
En maîtrisant ainsi votre VRAM et vos scripts de déchargement, vous ne maximisez pas seulement la puissance de votre GPU : vous optimisez sa durée de vie et votre propre productivité.