
L’industrialisation de l’Intelligence Artificielle générative bascule désormais vers une optimisation drastique de l’inférence en production. En ce début d’année 2026, Microsoft franchit une étape décisive avec le Maia 200. Gravé en 3nm, cet accélérateur n’est pas une simple itération, mais une rupture technologique conçue pour l’écosystème Azure. Cette analyse dissèque les performances de ce nouveau monstre de silicium face à ses concurrents directs : les AWS Trainium3 et Google TPU v7.
1. Analyse Technique : La suprématie du 3nm et Précisions Réduites
Le Maia 200 repose sur une architecture de pointe utilisant le nœud de gravure 3nm. Cette finesse permet d’intégrer une densité de transistors supérieure tout en maîtrisant l’efficience énergétique, point critique pour la viabilité économique des datacenters.
La force de Maia 200 réside dans sa gestion des précisions réduites (FP4/FP8), essentielles pour l’inférence des modèles de langage massifs. Contrairement à l’entraînement qui nécessite une précision élevée, l’inférence sur Maia 200 est optimisée pour un débit maximal. Avec 10 145 TFLOPS en FP4, il quadruple quasiment les performances de l’AWS Trainium3. Cette spécialisation permet d’exécuter des modèles complexes avec une latence « time-to-first-token » extrêmement basse.
2. Benchmark Comparatif : Positionnement sur le Silicium Propriétaire
Le tableau ci-dessous met en lumière le positionnement agressif de Microsoft. Le Maia 200 ne se contente pas de dominer sur le calcul brut ; il résout également le goulet d’étranglement majeur de l’IA : le mouvement des données.
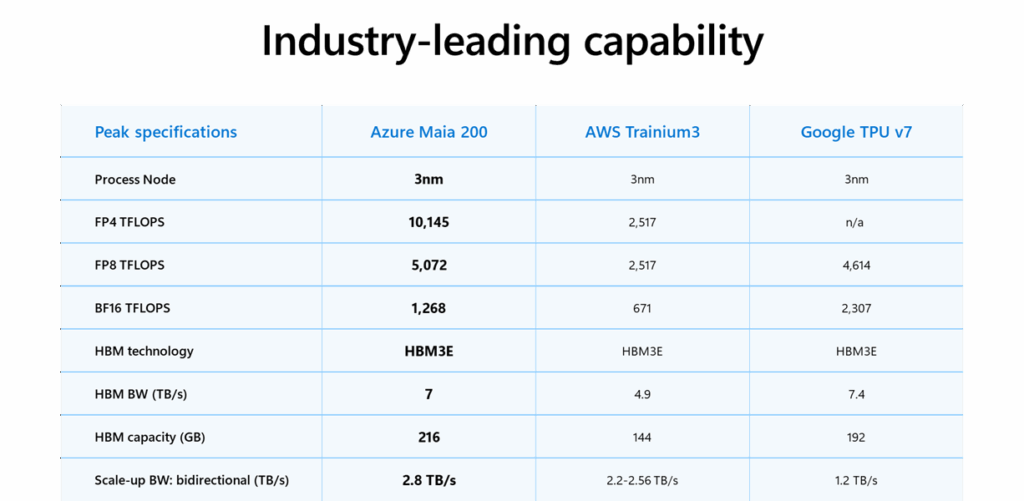
Si Google conserve un avantage sur le format BF16, Microsoft domine outrageusement sur les formats d’inférence et la capacité mémoire. Avec 216 Go de HBM3E et une interconnexion (Scale-up BW) de 2.8 TB/s, le Maia 200 garantit que les unités de calcul ne sont jamais en attente de données, même sur des modèles dépassant les 1.8 trillion de paramètres.
3. Impacts sur l’Infrastructure : Densité et Refroidissement
Le déploiement de telles capacités transforme radicalement le design des centres de données Azure.
3.1 Refroidissement Liquide Direct (DLC)
Dissiper la chaleur thermique générée par une telle densité de calcul nécessite l’abandon du refroidissement par air traditionnel. L’infrastructure accueillant le Maia 200 repose sur des boucles de refroidissement liquide directement sur puce. Pour les exploitants, cela signifie une transition vers des racks « hydrauliques » haute densité, optimisant le PUE (Power Usage Effectiveness) global.
3.2 Topologie de Cluster et Scale-up
Le Scale-up BW de 2.8 TB/s permet de créer des domaines de cohérence mémoire très larges. Cela simplifie le partitionnement des modèles (Model Parallelism) et permet aux instances Azure d’offrir une flexibilité accrue pour les entreprises souhaitant déployer des modèles « MoE » (Mixture of Experts) particulièrement gourmands en bande passante d’interconnexion.

4. Recommandations Pragmatiques
- Optimisation de la Quantification : Les équipes MLOps doivent prioriser la quantification de leurs modèles vers le format FP4 pour exploiter le plein potentiel du Maia 200.
- Stratégie FinOps : Évaluez le passage vers les instances Maia dès leur disponibilité générale. Le gain de performance par watt et par dollar sur l’inférence devrait réduire les coûts opérationnels de production de 30%.
- Portabilité via ONNX : Utilisez ONNX Runtime pour assurer une transition fluide de vos modèles entraînés sur GPU Nvidia vers ces ASIC propriétaires sans réécriture de code.
Conclusion
Le Maia 200 confirme la maturité de Microsoft en tant que fondeur. En surpassant ses concurrents sur presque tous les indicateurs clés de l’inférence, Redmond s’assure une indépendance stratégique et une avance technologique majeure pour l’ère de l’IA souveraine.